Pythagorean Theorem: the sum of the squares of the length of the legs of a right triangle is equal to the square of the hypotenuse.
The Pythagorean theorem is perhaps the most famous statement in all of mathematics. $a^2 + b^2 = c^2$ is practically drilled into the minds of everyone that went through any form of secondary school education.
But let me ask you: how do you know it is true? It's not like you've looked at every right triangle and checked it follows the theorem. There are many, many proofs of the Pythagorean theorem, but what makes you know that those fancy symbol manipulation is really legit? This might seem like an inane question, for math follows strict, rigorous, logical argument. But what makes this logical argument valid? Why do we trust logic so readily? There are many ideas that are intuitive that are false, and unintutive that are true, yet logic seems to get a pass from everyone? Why?
Over the past year, I took my university's introductory sequence for logic, which were probably the most enlightening classes I've ever taken. It forced me to reflect on not only what mathematics meant to me, but also what knowledge and deduction as a whole does too. This post is a summary collecting the highlights of the courses, so to act as a checkpoint to refer back to from future posts when I explore some of the most powerful ideas that have eluded me in what feels like a forgotten field of study.
As this will be a (quite a) bit of a longer post, the table of contents below will guide each section in the sequence they should be read, and all context needed for one section will be given in anything before it. I'll be following the conventions and terminology as per V. Halbach's The Logic Manual and A. Eagle's Elements of Deductive Logic. Brief examples will be given, but for more examples and exercises, see the texts above. For the best viewing experience, read this on a computer or wider-screen device for the equations to format as they were intended to be.
Table of Contents
- The Language of Logic
- Introduction to Metatheory
- Soundness and Completeness
- What's Next?
- Conclusion
Part 1: The Language of Logic
What Even is Logic?
English is bad. Notoriously so. Try interpreting the following sentence: "The old man the boat." This might not even read as a correct sentence to some of you. The lexical ambiguity in that "man" is being used as a verb, even if it is more commonly a noun, is what makes this sentence lead one astray. Or, what about, "The professor said there would be an exam on Monday." Does the professor mean there will be an exam to be taken on the upcoming Monday, or was it that this past Monday he claimed there would be an exam in the indeterminate future? The structural ambiguity inherent to what "on Monday" qualifies makes the sentence on its own unclear.
English—and natural language as a whole—relies on expectations being met by both the speaker and listener for effective communication. We'll touch on this more later, but the inherent vagueness of our language, while gives it the nuance that we praise in art and literature, makes it really hard to analyze the truth of what people claim when they talk, especially in writing. Inflection and tone may give cues to what is precisely being said, but sometimes we want the content of our statement to be independent of any necessary human interpretation or judgement.
Take the following claim: "If Socrates is a man, then he is mortal. Socrates is a man. Therefore, Socrates is mortal." Few would dispute this argument, but there is very little content we needed to be okay with this argument. We don't care who Socrates is, or what it means to be a mortal or a man; there is something embedded into the nature of the argument that makes it good. "The Earth is flat if 2+2=5. 2+2=5. Thus the Earth is flat," is a perfectly good argument assuming that 2+2=5, so while it might not be true, it certainly is still a good inference given those facts. "If $P$, then $Q$. $P$. Therefore, $Q$," seems to always be a sound claim.
Logic, in this way, is the study of valid arguments. Given a set of premises, what conclusions can we deduce?
$\mathcal{L}_1$: A First Attempt
Above we already were able to begin generalizing a little bit. We came up with the general form, "If $P$, then $Q$. $P$. Therefore, $Q$." $P$ and $Q$ could be almost any sentence, and that argument would always hold. Almost any sentence, in that our sentences have to be truth evaluable; parsing questions or exclamations does not elicit any new information for our claims, so it does not really make sense to consider them. Even if we do not know if $P$ and $Q$ are actually true or false, we can still consider the different cases to check our argument structure.
Here we have the beginning of our first formal language: the logic of $\mathcal{L}_1$. We have already been able to characterize sentences in the form of sentence letters i.e. $P$ and $Q$, but if we need more we can add $R$, $P_2$, $Q_{3984}$, and others if we need more basic sentences (by convention, only $P,Q,R$ are the allowable sentence letters, with additional ones being subscripted). But this is a bit primitive.
Connectives
What makes arguments in English interesting is not the basic sentences, but how we are able to link them together via "If… then…", "…and…", "…or…", and other conjunctions. Can we formalize these in any way?
Let's think about a simple one: "…and…". Just like before, we can only care about sentences that are true or false, so a natural question will be when is " $P$ and $Q$ " true or false? "…and…" unifies two disparate sentences, so if the whole sentence was true, we would expect what ever is on either side of the "and" to also be true. To say that, "Grass is green and the Earth is flat," is a true sentence seems to ignore what the sentence is claiming. "…and…" states both subsentences "Grass is green" and "The Earth is flat" together at once, so if we think it is true, then both necessarily seem to have to be true, too. We can represent this as a truth table.
where $T$ means the sentence is true and $F$ false. Whenever $P$ and $Q$ are not both true, there conjunction is not either. As seen in the table above, we don't write "…and…" in $\mathcal{L}_1$, but rather use the symbol $\wedge$.
We call $\wedge$ a connective, for it connects two sentence letters together. Below are some other commonly used English connectives formalized in $\mathcal{L}_1$ with their corresponding truth tables.
\begin{array}{c|c|c} P & Q & (P \wedge Q) \\ \hline T & T & T \\ T & F & F \\ F & T & F \\ F & F & F \\ \end{array} \\ \hline \textrm{…or…} & \ \vee \ \ &
\begin{array}{c|c|c} P & Q & (P \vee Q) \\ \hline T & T & T \\ T & F & T \\ F & T & T \\ F & F & F \\ \end{array} \\ \hline \textrm{It is not the case that…} & \neg &
\begin{array}{c|c} P & \neg P \\ \hline T & F \\ F & T \\ \end{array} \\ \hline \textrm{If…then…} & \rightarrow &
\begin{array}{c|c|c} P & Q & (P \rightarrow Q) \\ \hline T & T & T \\ T & F & F \\ F & T & T \\ F & F & T \\ \end{array} \\ \hline \textrm{…if and only if…} & \leftrightarrow &
\begin{array}{c|c|c} P & Q & (P \leftrightarrow Q) \\ \hline T & T & F \\ T & F & T \\ F & T & T \\ F & F & F \\ \end{array} \\ \end{array} $
It's worth taking a second to make sure you can get behind that these formalizations are reasonable. I won't go through all of them as we did with "…and…", but there are some things to take note of that do differ a bit in English.
- $\vee$ is specifically the truth table of inclusive or. In English, if one says "I'll either buy a pair of sneakers or sandals," we expect that person to usually just buy one option or the other, not both. $\vee$ allows the option for both, but does not require it to be true.
- $\rightarrow$ is technically different from "If…then…", even though I put them in the same row in the table. When we say, "If a butterfly lands in North America, then there will be a earthquake in Australia tomorrow", we can definitely say that is false if the butterfly does land in North America and no earthquake occurs, since they are definitely not causally related then. But if the butterfly does NOT land in North America, then we are in no position to say whether or not there is a relationship then since we have nothing to observe. Similarly, if an earthquake happens, we can't say if that was because of the butterfly or not regardless of what happens since correlation and causation are different. So really, the truth table for "If…then…" is
$ \begin{array}{c|c|c} P & Q & \textrm{If} \ P \ \textrm{then} \ Q \\ \hline T & T & ? \\ T & F & F \\ F & T & ? \\ F & F & ? \\ \end{array} $ We say it is not truth functional for those question marks there since we cannot evaluate whether that sentence is true or not, but for the sake of convenience, we use $\rightarrow$ with the completed table.
The Syntax and Semantics of $\mathcal{L}_1$
Now, we can upgrade from sentence letters to complex sentences in our logic. We will define a sentence in $\mathcal{L}_1$ as follows:
- All sentence letters $P, Q, R, P_1,…$ are sentences.
- If $\Phi$ and $\Psi$ are sentences, then $\neg\Phi$, $(\Phi \wedge \Psi)$, $(\Phi \vee \Psi)$, $(\Phi \rightarrow \Psi)$, and $(\Phi \leftrightarrow \Psi)$ are sentences.
- Nothing else is a sentence.
Note the use of parantheses to bracket the sentences. This is our way to remove all structural ambiguity by clearly stating the scope of the connectives; there is no question that $(P \wedge (Q \vee R))$ is different from $((P \wedge Q) \vee R)$ as the parantheses explicitly denote the scope of the connectives to what subsentences they are linking together. There are conventions to remove these brackets for convenience, which I may default to later, but as a whole, are not important.
The last detail we are missing are interpretations. Before, we were talking about how logic does not care about human judgement, but we can consider the judgement of the universe. What is the truth value of the sentence $\neg(P \wedge Q \rightarrow P \vee R)$? We could make a truth table, but clearly the truth of the sentence depends on the truth values of $P$, $Q$, and $R$. So under an $\mathcal{L}_1$-interpretation or $\mathcal{L}_1$-structure that assigns a truth value to every sentence letter, we can assign truth values to sentences. For example, if we let a structure $A$ be such that $|P|_A = T$, $|Q|_A = T$, and $|R|_A = F$, then $|\neg(P \wedge Q \rightarrow P \vee R)|_A = F$ by its truth table. The idea of a structure is that it is a model of a universe, where we designate certain sentences/facts to be true or false, and see how the rest of the other complex facts (that are linked by connectives) change in accordance to that possible universe.
Notation: $|\cdot|_A$ will stand for the meaning or semantics under a structure $A$.
Now most logical sentences one encounters will be true sometimes, and false sometimes depending on the structure its evaluated in. But consider the sentence $(P \vee \neg P)$. Looking at its truth table,
Every structure assigns a truth value to every sentence letter, so $P$ must be true or false in every structure, but regardless, $(P \vee \neg P)$ is always true. Tautologies or logical truths are in a sense, facts of nature, for no matter what universe we are looking at, "Either the sky is blue or it is not" will be true. At least, usually.
On the other hand, contradictions like $(P \wedge \neg P)$ are false in every structure.
For future reference, the following notation will be helpful. For a given structure $A$ and sentences $\Phi$ and $\Psi$ :
- If $|\Phi|_A = T$, we say $A$ satisfies $\Phi$, written $A \vDash \Phi$
- If $|\Phi|_A = F$, we say $A$ does not satisfy $\Phi$, written $A \nvDash \Phi$
- If $\Phi$ is a tautology, i.e. $A \vDash \Phi$ for all structures $A$, we just write $\vDash \Phi$
- If $\Phi$ is a contradiction, i.e. $A \nvDash \Phi$ for all structures $A$, we just write $\Phi \vDash$
- If $|\Phi|_A = |\Psi|_A$ for all strucutres $A$, we say $\Phi$ and $\Psi$ are logically equivalent, written $\Phi \equiv \Psi$
The last bullet point is just to say that there are lots of sentences that express the exact same truth table despite being written differently. For example, $P \rightarrow Q \equiv \neg P \vee Q$, so it's useful to say when to sentences are actually essentially the same.
Sets of Sentences
In addition to the semantics of individual sentences, we can discuss sets of sentences too. Consider $\Gamma = \{\Phi, \Psi,…\}$.
- A structure $A$ satisfies $\Gamma$ if and only if $|\gamma|_A = T \ \ \ \forall \gamma \in \Gamma$, written $A \vDash \Gamma$
- We say $\Gamma$ is consistent or satisfiable if and only if there is a structure $A$ such that $A \vDash \Gamma$
Validity of an Argument
We are finally in a position to start talking concretely and specifically what makes a good argument.
When someone has argued a claim (conclusion) from a series of facts and assumptions (premises), we want there to be a substantive connection between their premises and the conclusion. Just like with our truth table for "If…then…", we know there is no connection if there is a scenario in which our premises are true and our conclusion isn't. So if an argument is valid, then whenever the premises are true, the conclusion must also be true.
We can formalize this a little bit with the notion of semantic entailment:
Definition: Given a set of sentences (premises) $\Gamma = \{\Phi, \Psi,…\}$ and a single sentence $\varphi$ (conclusion), we say that $\Gamma$ semantically entails $\varphi$ if and only if for all structures $A$, if $A \vDash \Gamma$, then $A \vDash \varphi$.
In other words, whenever all of our premises are true, our conclusion is true.
When $\Gamma$ semantically entails a sentence $\varphi$, denoted $\Gamma \vDash \varphi$, then $\varphi$ is a valid conclusion from premises $\Gamma$. It's called semantic entailment since we are working with the semantics of the individual sentences, namely their truth values. In the language of consistency, we can also say that $\Gamma \vDash \varphi$ if and only if $\Gamma \cup \{\neg \varphi\}$ is inconsistent.
Claim: $\Gamma \vDash \varphi$ if and only if $\Gamma \cup \{\neg \varphi\}$ is inconsistent.
Proof: Suppose that $\Gamma \vDash \varphi$. Say that $A$ is a structure that satisfies $\Gamma$ i.e. $|\gamma|_A = T \ \ \ \forall \gamma \in \Gamma$. Then by our assumption, $|\varphi|_A = T$. By the rules for $\neg$, then $|\neg \varphi|_A = F$. For any structure $B$ that does not satisfy $\Gamma$, $\exists \gamma \in \Gamma \ \ \ |\gamma|_B = F$. So, for all structures, at least one sentence in $\Gamma \cup \{\neg \varphi\}$ is false, so it is inconsistent. $ \ \blacksquare$
It's worth pointing out that we have two uses for the symbol $\vDash$, one relating structures to sentences, and another relating sentences to other sentences. The context will specify which use we mean, but it is useful to keep in mind that we might double up on symbols when their related meanings are so similar.
Let's look at the example we've been holding this whole time: "If $P$, then $Q$. $P$. Therefore, $Q$." If this is a valid argument, then the formalization would say that $P \rightarrow Q, P \vDash Q$ is correct. We can verify this just by truth tables:
Whenever the premises are true, so is the conclusion. While technically an okay way to check, it is inefficient. Imagine we had an argument with not 2, but even just 3, 4, or more sentence letters, since for every additional sentence letter in our premises, it doubles the number of rows in our truth table to check. Instead, we can show it just as easily with a proof by contradiction. Suppose our argument is invalid i.e. there is a structure where our premises are true and our conclusion is false.
But, if $P$ is true and $Q$ is false, then by the rules for $\rightarrow$, we have $P\rightarrow Q$ is false.
That contradicts our assumption that $P\rightarrow Q$ was true as a premise. So, it can't be the case that our argument is invalid.
Quicks of Validity
Keep in mind our definition of a valid argument: $\Gamma \vDash \varphi$ if and only if whenever $\Gamma$ is satisfied, so is $\varphi$. Now consider the argument $P \wedge \neg P \vDash Q$. Is this valid? Even though the premises have nothing to do with the conclusion, surprisingly, this is valid. $P \wedge \neg P$ technically satisfies the condition that whenever it is true (never), so is $Q$; it never has the chance to fail our definition. For this we can write $P \wedge \neg P \vDash$ since it will entail everything by our definition, and anything can go on the right hand side of the turnstile, and this is why we shorten all contradicitions accordingly.
Similarly, we can do the same for tautologies, $\vDash P \vee \neg P$ since they will always be true, so certainly whenever whatever on the left is true, so is the tautology.
So we can have weird technically valid arguments like, "The sky is blue and not blue, therefore the Earth is flat," or similarly that "Squares have 5 corners, so either it will rain today or it won't." These both read as absurd, but they are technnically valid with our definition. These might seem like a flaw for our definition, but for the convenience of all the other arguments, I think it is worth accepting as an oddity of the system. You can also think of them as just sort of fact-of-the-matter statements; tautologies are entailed by everything since they don't care what makes you think they are true, they just are. Similarly with contradictions, your starting set of premises are just inconsistent, and it is just a bad argument; if you're willing to accept bad premises, you can deduce bad conclusions.
Proof Systems and Natural Deduction
We have established quite a bit already in $\mathcal{L}_1$, but it is still not that elegant of a system. We now have a way to formalize English arguments, but our ways to validate them are still unwieldy. The only two ways we really have to verify statements is, in essence, brute force checking $\mathcal{L}_1$-structures to see if the argument fails anywhere. This is no better than checking every right-angled triangle to see if it satisfies the Pythagorean theorem. We want a systematic way to go about our arguments.
We want a proof system: given a set of premises $\Gamma$, we want to be able to manipulate them in some way to conclude $\varphi$.
For example, consider the argument $P \wedge Q, R \vDash P \wedge R$. Without checking any structures and evaluating truth tables, this argument should make sense. If we know $P \wedge Q$, i.e. $P$ and $Q$, we certainly know both $P$ and $Q$ are true individually, so we know $P$. Since we also know $R$ is true, then again it seems obvious we know $P$ and $R$ is also true together i.e. $P \wedge R$. We did not touch any semantics at all of our premises or conclusion (I used the word "true" as a means for accepting a premise), but rather just moved our sentence letters around in a sensible way to get the conclusion.
We just found two rules that make sense to have in our proof system: $\wedge$-Introduction and $\wedge$-Elimination.
So our above proof of $P \wedge Q, R \vdash P \wedge R$ would look like
Thinking through what the other connectives mean can give some intuitive rules for them too:
& \begin{array}{c} \Phi \wedge \Psi \\ \hline \Phi \\ \end{array} \ \ \ \ \begin{array}{c} \Phi \wedge \Psi \\ \hline \Psi \\ \end{array} \\ \hline \vee & \begin{array}{c} \Phi \\ \hline \Phi \vee \Psi \\ \end{array} \ \ \ \ \begin{array}{c} \Psi \\ \hline \Phi \vee \Psi \\ \end{array} & \begin{array}{c} \begin{array}{ccc} & [\Phi] & [\Psi] \\ & \vdots & \vdots \\ \Phi \vee \Psi & \Delta & \Delta \\ \end{array} \\ \hline \Delta \end{array} \\ \hline \neg & \begin{array}{c} \begin{array}{cc} [\Phi] & [\Phi] \\ \vdots & \vdots \\ \Psi & \neg\Psi \\ \end{array} \\ \hline \neg \Phi \end{array}
& \begin{array}{c} \begin{array}{cc} [\neg\Phi] & [\neg\Phi] \\ \vdots & \vdots \\ \Psi & \neg\Psi \\ \end{array} \\ \hline \Phi \end{array} \\ \hline \rightarrow & \begin{array}{c} [\Phi] \\ \vdots \\ \Psi \\ \hline \Phi \rightarrow \Psi \\ \end{array}
& \begin{array}{c} \begin{array}{cc} \Phi & \Phi\rightarrow\Psi \\ \end{array} \\ \hline \Psi \end{array} \\ \hline \leftrightarrow & \begin{array}{c} \begin{array}{cc} [\Psi] & [\Phi] \\ \vdots & \vdots \\ \Phi & \Psi \\ \end{array} \\ \hline \Phi\leftrightarrow\Psi \end{array}
& \begin{array}{c} \begin{array}{cc} \Phi & \Phi\leftrightarrow\Psi \\ \end{array} \\ \hline \Psi \end{array}
\ \ \ \ \begin{array}{c} \begin{array}{cc} \Psi & \Phi\leftrightarrow\Psi \\ \end{array} \\ \hline \Phi \end{array} \\ \end{array} $
The square brackets are assumed premises. They are not explicitly given, but, for the sake of argument, you can take a "fake" premise to demonstrate a rule, and discard that assumption after you've used your rule. Some other comments on the rules:
- $\vee$-Intro basically says if you know one sentence, appending any other sentence via $\vee$ is certainly fine since you already have a known fact. $\vee$-Elim says if you know one or the other (or both) of $\Phi$ and $\Psi$ is true, but do not know which, you can deduce a new sentence $\Delta$ if it follows from either of the sentences.
- $\neg$-Rules are basically proofs by contradiction. If $\Phi$ results in both $\Psi$ and $\neg\Psi$, $\Phi$ can't be held true since it would prove contradictory results. Similarly with assuming $\neg\Phi$.
- $\rightarrow$-Intro follows in line with for-the-sake-of-argument. If we assume $\Phi$, and can deduce $\Psi$, then regardless if we know $\Phi$ or not, we can say that it would logically imply $\Psi$ as well.
This specific proof system is known as natural deduction. These proof trees give us a direct way to interact with our premises in a way that we might normally do in English. However, some of these proofs do become huge quite quickly. Consider the proof of $P\rightarrow (Q\leftrightarrow R) \vdash P \wedge Q \leftrightarrow P \wedge R$:
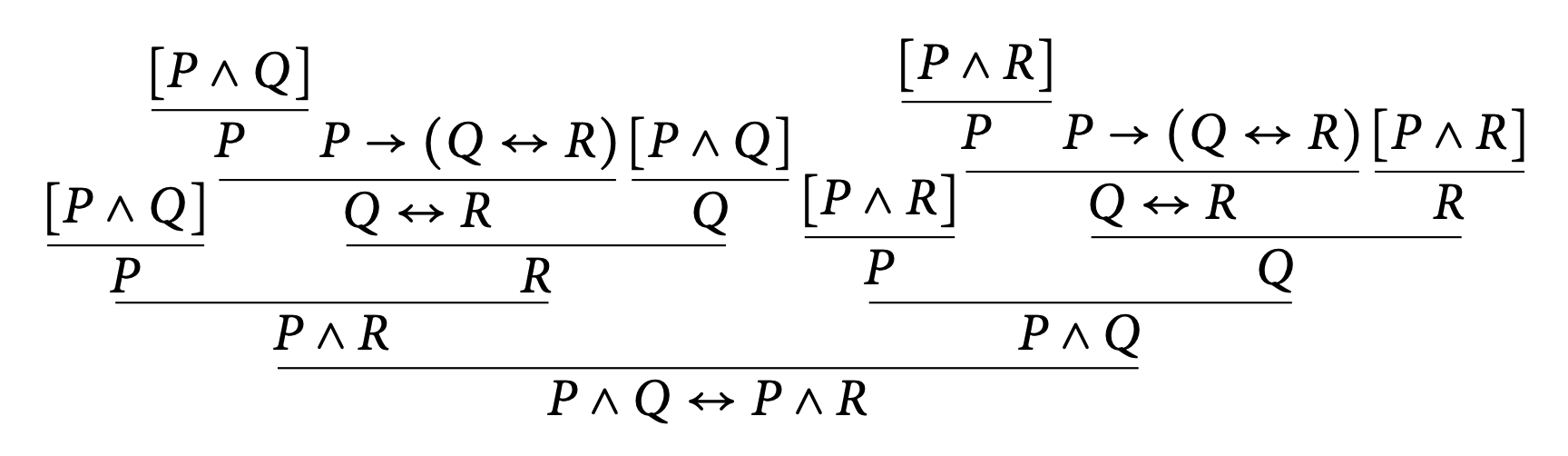
Some of you might have noticed a small change in notation; I've been using $\vdash$ as opposed to $\vDash$. In proofs, since we are not considering structures and the truth values of our sentences, semantic entailment does not seem like the right way to describe the relationship between our premises and the conclusion. We now say $\Gamma \vdash \varphi$ if $\Gamma$ syntactically entails, or simply proves via our proof system, $\varphi$, since we are strictly only concerned with the symbols and the actual writing of the sentence as opposed to its truth.
But we should not forget our original goal of logic: to demonstrate arguments are valid, which involves $\Gamma \vDash \varphi$, which seems to have a very different meaning to $\Gamma \vdash \varphi$. It happens that our choice of rules above was not random. As we will see later, natural deduction is a sound system:
Soundness Theorem: If $\Gamma \vdash \varphi$, then $\Gamma \vDash \varphi$.
Soundness can be thought of as the quality of preserving truth; we can rely on our proofs to deduce meaningful, accurate conclusions in our formal language. Given our rules, we would hope that these are sound, since they are based on how people typically argue in real life, too. You might come across other proof systems, but I can guarantee you, they are designed to be sound and useful.
It's worth mentioning at this point we have similar notions for consistency in a proof based sense just as we have in a semantic sense. We say a set of sentences $\Gamma$ is ND-consistent (ND for natural deduction) if there exists a sentence $\Phi$ that $\Gamma$ does not prove; i.e. $\exists \Phi$ s.t. $\Gamma \nvdash_{ND} \Phi$. In general, we say $\Gamma$ is D-consistent if there is a sentence $\Gamma \nvdash_{D} \Phi$ in the deductive system $D$. A good way of thinking about this is if we have bad premises, we can deduce anything since our assumptions were contradictory in some way. For example, $\{P, \neg P\}$ is ND-inconsistent since by $\neg$-Elim, it can prove anything.
Fortunately enough for us, ND-consistency is equivalent to semantic consistency, but we'll see that later.
This concludes our discussion of $\mathcal{L}_1$. The system and rules we've outlined above is sometimes also referred to as propositional logic.
$\mathcal{L}_2$: The Logical Quantifiers
Let's go back to our very first argument we discussed: "If Socrates is a man, then he is mortal. Socrates is a man. Therefore, Socrates is mortal." We were able to show it is valid in $\mathcal{L}_1$ by formalizing it, and either checking its truth table or with our proof system. Let's look at a very similar argument. "All men are mortal. Socrates is a man. Therefore, Socrates is mortal." Perfectly reasonable. If we formalize this with our current logic, though, we end up with $P, Q \vDash R$, where $P$ is "All men are mortal," $Q$ is "Socrates is a man", and $R$ is "Socrates is mortal". Clearly this is not a logical argument in $\mathcal{L}_1$, since we can just specify a structure where $|P|_A = |Q|_A = T$ and $|R|_A = F$ since they are separate sentence letters.
Predicates and Constants
$\mathcal{L}_1$ is good for keeping sentences simple, but it lacks the nuance of the predicates English has; we will never be able to show the relation of men and mortality, as we can't express "…are mortal" nicely; relations between simpler sentences are covered by connectives, but relations between objects are not. We need something to convey properties somehow. Ideally, we want to be able to say Socrates is mortal, by first saying he is a man, and to further show that anything that has the property of being a man also has the property of being mortal.
To formalize "Socrates is a man", we can introduce predicates kind of like connectives. Let's have $P^1$ stand for "…is a man", and for convenience, we'll let the letter $|a|_A$ stand for the constant Socrates (remember, $|\cdot|_A$ denotes meaning). Then $P^1a$ is a nice compact way to write out "Socrates is a man".
Now how do we formalize that this is a true sentence? We don't want to have to explicitly say $|P^1a|_A = T$, since then we would have to specify that for everything that is a man, there is a constant associated with that human and that when put together with $P^1$ forms a true statement.
Let's take a step back for a moment. If you had to explain to an alien precisely what a human is, how would you do it? You might describe some key traits for them, but the easiest way, in a universal sense, is just to show them by example. Give them a list of humans and have them extrapolate on their own. So perhaps a good semantics for predicates is to exactly that: we will let $|P^1|_A = \{\textrm{Socrates}, \textrm{Feynman}, \textrm{Noether},…\}$.
Then a natural way of defining truth would be that $|P^1a|_A = T$ if and only if $|a|_A \in |P^1|_A$. That sentence makes sense, since $|a|_A$ is an object/noun, and $|P^1|_A$ is a set of objects, so we can evaluate that, and since $|P^1|_A$ explicitly states all the objects that have that property, seeing if something has that property (like being a man) is a matter of being in the list of objects said to have it. "Socrates is a man" is true iff "Socrates" has the property "is a man" iff Socrates is in the set of all men.
I've been putting a small superscript in our predicate $P^{\color{red}{1}}$. This is the arity index, and basically says how many objects the predicate takes as an input. So, naturally we can have indices greater than 1 as well.
The predicate "…like…" is a perfectly good predicate, but it now qualifies two objects and relates them to each other. So if Alice likes Bob, we can write this as $P^2ab$ with the relevant meanings for $P^2$ as "…likes…" and the constants referring to Alice and Bob respectively. But note here, order matters. Just because Alice likes Bob, that does not necessarily mean Bob likes Alice and so for some structures it might be the case that $|P^2ab|_A \neq |P^2ba|_A$.
Just as arity 1 predicates had a set of objects as its semantics, arity 2 has a set of ordered pairs i.e. $|P^2|_A = \{\langle \textrm{Alice}, \textrm{Bob}\rangle, \langle \textrm{Davis}, \textrm{Edward} \rangle, \langle \textrm{Jack}, \textrm{Jack} \rangle \}$ would be a reasonable way to denote the predicate. And similarly, we say $|P^2ab|_A = T$ if and only if $\langle |a|_A, |b|_A \rangle \in |P^2|_A$. So 2-ary predicates define binary relations.
In practice, the arity index usually doesn't need to be written, as it will be implied by the number of constants attached to the predicate i.e. $Pabc$ is clearly a ternary predicate, as if it wasn't, it would either be incomplete ("a hates b and c, but likes ?"), or it would accept too many arguments ("If a then b"; where does c go?). So in sentences like $Pa \wedge Pab$, each $P$ stands for a different predicate as implied by their arity.
This is the start of the more robust logic $\mathcal{L}_2$. Just for the formalities, here are some things we need to keep in mind over $\mathcal{L}_1$.
- Sentence letters are the same as 0-ary predicates; they accept no arguments.
- In an $\mathcal{L_2}$-structure, we assign semantics to every predicate (either truth values or sets to predicates), as well as an object to every constant
- Connectives work the same as they have done before
- Truth for predicates are equivalent to membership of a set
Quantifiers
So we now have a good way of storing properties of objects via the predicates they satisfy, so we have a good way of saying "Socrates is a man". But now we need a way of saying, "All men are mortal". It's that "all" that makes this difficult, since it does not refer to a specific man, but a generic one.
Let's generalize the sentence a bit more. What it really is saying, "If one is a man, then they are mortal." Now we have this nice "one" acting a placeholder name for our generic man. Actually, for a generic anything. If we are talking about a turtle, we cannot say if they are mortal by this sentence since they have nothing to do with that claim.
In an even more mathematical way of looking at the sentence, it could read as, "For all $x$: if $x$ is a man, then $x$ is mortal." That "for all" appears enough in arguments, we have formalize it as $\forall$, the universal quantifier. You might have seen this appear in math, and if not, I've already been abusing its convenience in some previous proofs on this post.
So our sentence would look like $\forall x(Px \rightarrow Qx)$ where $P$ and $Q$ are predicates for being a person and mortal respectively.
$x$ is clearly not a constant, since, well, it is not constant; it does not have a fixed meaning. We then aptly call it a variable. But clearly, variables can take on certain meanings, so we also have variable assignments $\alpha, \beta,…$ that allow us to arbitrarily assign variables meanings in a formal way. For example, if we let $x$ mean Socrates in our structures, i.e. $|x|_A^\alpha = \textrm{Socrates} = |a|_A$, then our argument works by the truth rules for $\rightarrow$.
The "opposite" of the universal quantifier is the existential quantifier $\exists$, which instead of saying our sentence applies to all possible objects, $\exists x \Phi$ only claims that there is at least one object that satisfies the sentence $\Phi$.
The duality of the quantifiers can be found even in natural language. "Everything is not a cow," as in $\forall x \neg Px$, is the same as saying, "There does not exist a cow", or $\neg \exists x Px$. Similarly, "There is something that is not a cow," or $\exists x \neg Px$, is equivalent to saying "Not everything is a cow" or $\forall x \neg Px$.
However, not every formula with variables and quantifiers make a sentence. Consider $\forall x \exists y(Px \vee \neg Qxy \rightarrow Rz)$. This doesn't make that much sense since $z$ is just hanging out as a free variable as there is no quantifier claiming anything about $z$. And since $z$ is a variable, it's not like it has any semantic meaning, either. So we wouldn't call this a sentence, but a formula. Variables that are not free are bound.
Definition: A formula is a sentence if and only if it has no free variables.
Similarly, $\forall y Qy \rightarrow Py$ wouldn't be called a sentence either, as depite how it looks, there is a free variable in $Py$ even though there is a $\forall y$ in the formula. You usually need parantheses to specify what the quantifiers bind. $\forall y(Qy \rightarrow Py)$ is a sentence, while the previous expression is not.
Domains
The final extra detail we need is to specify what meanings our variables are allowed to be assigned. So in an $\mathcal{L}_2$-structure, we also specify a domain that specifies all the possible objects in the "universe" that we are discussing. All constants are assigned meanings from the domain, and our quantifiers use variable assignments that range over the domain.
Satisfaction and Truth in $\mathcal{L}_2$
Suppose $\Phi$ and $\Psi$ are $\mathcal{L}_2$ formulas, $v$ is a variable, $A$ is a structure, and $\alpha$ is a variable assignment. We say $\alpha$ satisfies $\varphi$ under $A$, or $|\varphi|_A^\alpha = T$, in the following way:
- $|\Phi v_1v_2…v_n|_A^\alpha = T$ iff $\langle |v_1|_A^\alpha, |v_2|_A^\alpha,…, |v_n|_A^\alpha \rangle \in |\Phi|_A^\alpha$ where $\Phi$ is an n-ary predicate and each $v_i$ is a variable or constant
- $|\neg\Phi|_A^\alpha = T$ iff $|\Phi|_A^\alpha = F$
- $|\Phi \wedge \Psi|_A^\alpha = T$ iff $|\Phi|_A^\alpha = T$ and $|\Psi|_A^\alpha = T$
- $|\Phi \vee \Psi|_A^\alpha = T$ iff $|\Phi|_A^\alpha = T$ or $|\Psi|_A^\alpha = T$
- $|\Phi \rightarrow \Psi|_A^\alpha = T$ iff $|\Phi|_A^\alpha = F$ or $|\Psi|_A^\alpha = T$
- $|\Phi \leftrightarrow \Psi|_A^\alpha = T$ iff $|\Phi|_A^\alpha = |\Psi|_A^\alpha$
- $|\forall v \Phi|_A^\alpha = T$ iff for every variable assignment $\beta$ that differs from $\alpha$ in at most $v$, $|\Phi|_A^\beta = T$; in other words, $|\forall v \Phi|_A^\alpha = T$ iff $\Phi$ is satisfied when every thing except $v$ is fixed
- $|\exists v \Phi|_A^\alpha = T$ iff there is at least one variable assignment $\beta$ that differs from $\alpha$ in at most $v$ where $|\Phi|_A^\beta = T$; in other words, $|\exists v \Phi|_A^\alpha = T$ iff $\Phi$ is satisfied for some value of $v$
The normal connective satisfaction come from the standard truth tables we did before, and the quantifiers are exactly what you would imagine them to mean, just formalized in the new terminology we have to make it precise.
The truth of an $\mathcal{L}_2$ sentence is now easy given the above satisfaction rules:
Definition: An $\mathcal{L}_2$ sentence $\varphi$ is true $|\varphi|_A = T$ iff $|\varphi|_A^\alpha = T$ for every variable assignment $\alpha$ over $A$.
Validity remains the same in $\mathcal{L}_2$, just with our updated definitions for structures and truth:
Definition: Given a set of $\mathcal{L}_2$ sentences $\Gamma = \{\Phi, \Psi,…\}$ and a single sentence $\varphi$, we say that $\Gamma$ semantically entails $\varphi$ if and only if for all $\mathcal{L}_2$-structures $A$, if $A \vDash \Gamma$, then $A \vDash \varphi$.
Natural Deduction 2.0
Rules for our original connectives $\wedge, \vee, \neg, \rightarrow, \leftrightarrow$ remain the same. We only need to add the rules for $\forall$ and $\exists$. It will be easier to write them out then explain them afterwards.
The notation of $\Phi[t/v]$ is to highlight substitution: $\Phi[t/v]$ is the formula $\Phi$ with all occurrences of $v$ in it replaced with $t$. For example, if $\Phi = Px \wedge \forall y (Qxy \rightarrow Rx)$, then $\Phi[t/x] = Pt \wedge \forall y (Qty \rightarrow Rt)$.
Here is the intuition behind the new rules:
- $\forall$-Intro basically says if $t$ is a constant that does not appear anywhere else in our proof, it is in practice a "dummy variable", and allows us to introduce a proper variable bound by $\forall$.
- $\forall$-Elim says if we know $\Phi$ is satisfied by possible $v$, it is certainly true if $v$ is replaced by a specific $t$; if all men are mortal, certainly Socrates is mortal too
- $\exists$-Intro is the formal way of saying if we see an occurence of $\Phi$, then there is some $v$ that satisfies $\Phi$; if you see a cow, you know there is at least one animal
- $\exists$-Elim is a for-the-sake-of-argument style proof. While we may not know exactly what satisfies $\exists v \Phi$, if we can deduce some claim independent of the specific thing that satisfies it, we know that claim must also be true as it only relies on the existence of something. If we know there is at least one plant-eating animal—call it Bob—we can conclude that there are plants, since Bob eats plants, and that's true for all "Bob"s (a.k.a. plant-eating animals).
With these added rules, we can now prove a lot of the things we already knew, such as:
- The mortality argument of $\forall x(Px \rightarrow Qx), Pa \vdash Qa$
- The quantifier interplay $\neg \forall x Px \dashv\vdash \exists x \neg Px$
- Standard tautologies and contradictions; $\vdash \forall x Px \vee \neg \forall x Px$, and $\forall x Px \wedge \neg \forall x Px \vdash$
Here is an example worked proof from the additional exercises of The Logic Manual of $\forall y \exists x(Ryx \vee Qyx) \vdash \forall y (\exists x Ryx \vee \exists x Qyx)$:
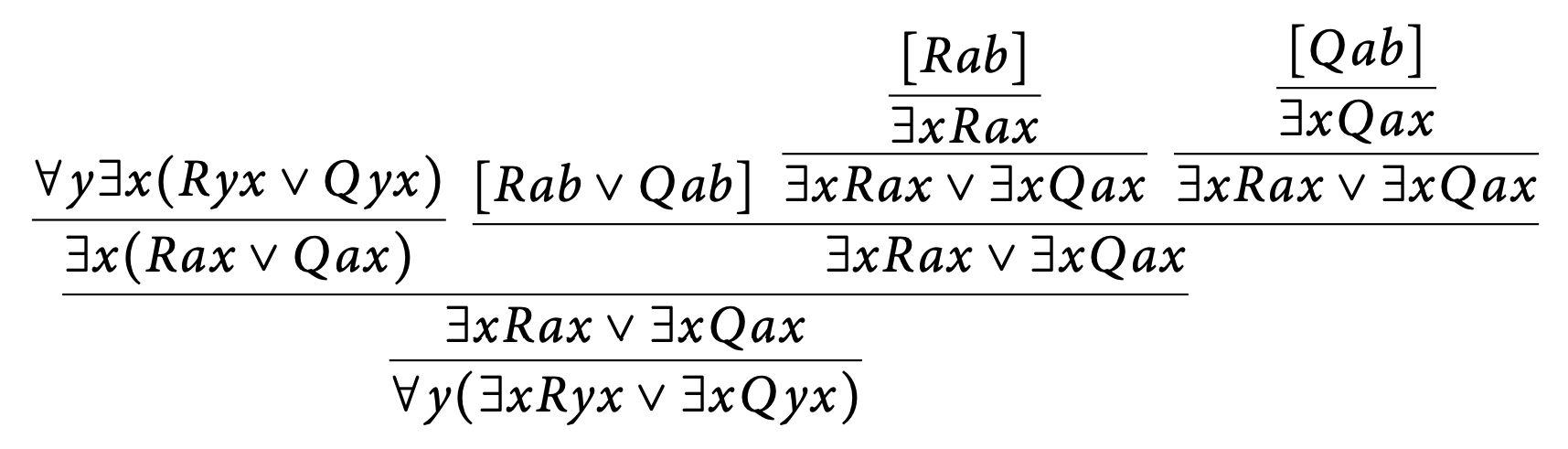
Similarly, we will see that these rules are also sound.
$\mathcal{L}_=$: Identity and Definite Descriptions
$\mathcal{L}_2$ gets us most of the way for what we want but there's one slight inconvenience: we don't have a notion of identity. Say we have a constant $a$ with semantic value $|a|_A = \textrm{Socrates}$. Then, if we have another constant $b$ such that $|b|_A = \textrm{Socrates}$, we have no good way of showing these constants are really "the same"; they might look different, but they function in the same way as both standing in for Socrates.
And in a philosophical, sense, identity is an important concept in ontologies and metaphysics, so it's worthwhile having a formal notion that we can refer to when picking apart arguments.
We could just specify the predicate, "…is identical to…" as a binary predicate letter in $\mathcal{L}_2$, but that means that the predicate might receive arbitrary meanings in different structures, and identity seems like a pretty unshakeable concept. It also might mean that we use different predicate letters in different formalizations, and we want this to be consistent for it to be useful.
This is what $\mathcal{L}_=$ is for. $\mathcal{L}_=$ is exactly like $\mathcal{L}_2$ in terms of structures and truth, but it has the one difference of having an extra predicate of $=$ to refer to identity. Some quick notes:
- As $=$ is a binary predicate, it relates two terms that are constants or variables (not formulas or sentences!)
- By convention, we write $a=b$ as per the norm of math; we don't write $=ab$ as we would for a normal predicate/predicate letter
- For variables/constants $s$ and $t$, $|s=t|_A^\alpha = T$ iff $|s|_A^\alpha=|t|_A^\alpha$ i.e. they share the same semantic value and represent the same object
Natural Deduction 2.5
We don't have much else to add alongside $=$, and the new rules we use are among the most intuitive of the lot.
- For all constants $a$, it is clear that $a$ is identical to itself, so the introduction rule allows us to say that whenever we want for any constant
- If $s$ and $t$ are identical, they can be swapped freely in formulas without hurting the underlying semantics, so the elimination rule also makes sense
Using these rules along side our normal natural deduction, try to prove that $=$ is an equivalence relation, that is
- It is reflexive: $\vDash \forall x (x=x)$
- It is symmetric: $\vDash \forall x \forall y (x=y \rightarrow y=x)$
- It is transitive: $\vDash \forall x \forall y \forall z (x = y \wedge y = z \rightarrow x = z)$
just as we would expect of normal identity.
Numerical Quantifiers and Definite Descriptions
With identity in place, we can now establish a surprising amount of additional, useful claims regarding the specifity of the objects we are talking about.
Numerical Claims
If we wanted to say, "There is at least 1 chicken", we can already do that with $\exists$ by letting $|P| = \textrm{"…is a chicken"}$ and the formalization $\exists x Px$. This is by definition of what it takes to satisfy $\exists$: it requires only one variable assignment, i.e. object in the domain, to be in the set of chickens that $P$ expresses.
If we want to say there are at least two chickens, then we can write there are two things that are chickens i.e. $\exists x \exists y(Px \wedge Py)$. But this alone does not guarantee there might be two chickens, since if there is one chicken, then the variable assignment where both $x$ and $y$ both refer to the same chicken would satisfy that sentence. So we add the clause that they are distinct: $\exists x \exists y(Px \wedge Py \wedge \neg x = y)$; the $\neg x = y$ prevents our variable assignments allowing $x$ and $y$ to be the same if we want
At least 3 chickens would be like $\exists x \exists y \exists z(Px \wedge Py \wedge Pz \wedge \neg x = y \wedge \neg x = z \wedge \neg y = z)$. At least $n$ chickens, would be $\exists x_1 \exists x_2 \cdots \exists x_n(\bigwedge_{i=1}^n Px_i \wedge\bigwedge_{1 \leq i < j \leq n} \neg x_i = x_j)$ where $x_i$ are variables and $\bigwedge$ is like $\sum$ where each term instead of being added is linked by the $\wedge$ connective.
Similarly, if we want at most 1 chicken, that is the same as saying the opposite of at least 2 chickens; the complement of $\geq 2$ is $<2$ or $\leq 1$. So we can just negate our sentence from before: $\neg \exists x \exists y(Px \wedge Py \wedge \neg x = y)$. A cleaner (and more intuitive way) to formalize this, in my opinion is the following: $\forall x \forall y(Px \wedge Py \rightarrow x = y)$; for every 2 supposedly different chickens, they are actually the same.
At most 2 chickens would be $\forall x \forall y \forall z(Px \wedge Py \wedge Pz \rightarrow x = y \vee x = z \vee y = z)$; if there are 3 supposedly different chickens, actually at least 1 is a duplicate of the other 2. For at most $n$ chickens: $\forall x_1 \forall x_2 \cdots \forall x_{n+1}(\bigwedge_{i=1}^{n+1} Px_i \rightarrow \bigvee_{1\leq i < j \leq n+1} x_i = x_j)$
Definite Descriptions
We can set lower bounds on how many chickens there are, and upper bounds on how many chickens there are, so we are now in place to formalize when there is exactly one chicken. For there to be only one supreme chicken, we just need to specify there is at least one and at most one chicken: $\color{blue}{\exists x Px} \wedge \color{red}{\forall x \forall y(Px \wedge Py \rightarrow x = y)}$. An even nicer expression is $\exists x (Px \wedge \forall y (Py \rightarrow y = x))$; there is something that is a chicken, and all other chickens are really the same as that original, defining chicken.
With this, we can now formalize definite descriptions. When we mention "The president of the United States", we are referring to a general position i.e. many people were president from George Washington to Joe Biden. However, there is only one current president of the U.S., and we are now able to differentiate the two with our formalizations above. "The president is a democrat" would be written as $\exists x (Px \wedge \forall y (Py \rightarrow y = x) \wedge Qx)$ where $P$ expresses "…is the president of the U.S." and $Q$ for "…is a democrat". In general to express, "The $\Phi$ has the property $\Psi$," we could use the following formula:
Russell's theory of definite descriptions: $\exists x (\Phi \wedge \forall y (\Phi[y/x] \rightarrow y = x) \wedge \Psi)$
With definite descriptions in hand, we can now formally prove arguments that naturally make sense in English. "Tim's car is red. Therefore there is a red car." Easy enough to see in English, but requires a bit more work to express in $\mathcal{L}_=$:
Generalized Numerical Quantifiers
We were able to specify exactly 1 thing satisfies a property, but we can generalize to exactly $n$ with a simple recursive definition. To express there are exactly $n$ things satisfying a formula, we will denote it with $\exists!_n$, given by the following definition:
- $\exists!_0 v \Phi = \neg \exists v \Phi$
- $\exists!_{n+1} v \Phi = \exists u (\Phi[u/v] \wedge \exists!_n v(\Phi \wedge \neg u = v))$
Exactly 0 things satisfy the formula $\Phi$ when there does not exist anything that satisfies it. Exactly $n+1$ things satisfy $\Phi$ when there is something that satisfies $\Phi$ and exactly $n$ distinct, other things that satisfy $\Phi$ as well. As a gut check, we can test to see if this agrees with our definition from definite descriptions from before.
By a series of logical equivalences, we can see that we get precisely what we expect.
A Quick Aside on Identity
We've been using identity loosely so far, since what we mean by "identical" actually varies, whether you realize it or not.
If we say my friend and I have identical cars, we don't mean that my friend and I literally own the same car, but rather the make, the model, the color, etc. all look identical. This is an example of (approximate) qualitative identity, where two objects share the same properties. However, if you say the police tell you your car is the same one that was seen at a crime scene, then we mean it is literally the one and the same car. This is numerical identity.
We have to be careful about this since these two types of identities clearly seem disparate. While numerical identity seems to imply qualitative identity (one thing will always share the same properties as itself), it is debated if qualitative identity really implies numerical identity. If two things really share all the same properties, it becomes unclear whether or not that really implies we are talking of the same object.
The language of $\mathcal{L}_=$ focuses on the latter numerical identity, even though the former might be the more convenient one in everyday speech.
Summary of our Logics
We've covered a lot, so let's quickly recap some of the key ideas covered so far:
- Logic studies valid arguments; what conclusions can we draw by nature of the structure of our argument?
For $\mathcal{L}_1$:
- We had basic sentence letters, which we made more complex with the connectives $\{\wedge, \vee, \neg, \rightarrow, \leftrightarrow\}$, each with their own set of truth rules
- We modelled the universe in the manner of structures, saying which sentences we said to be true and which to be false
- Alongside it came its own proof system, natural deduction, that allowed us to validate arguments in a more systematic way beyond brute force checking
For $\mathcal{L}_2$:
- We lacked the nuance of relating objects to each other in $\mathcal{L}_1$, so we introduced constants to formalize those objects with properties stored as predicates
- We updated our model of the universe with specifying constants and predicates (unary, binary, ternary, and n-ary relations)
- The universal $\forall$ and existential $\exists$ quantifiers were a nice shortcut to state claims of how many things in the domain satisfy a formula
- We updated our proof system to account for these quantifiers
For $\mathcal{L}_=$:
- The notion of numerical identity leads to obvious truths that would be convenient to introduce
- We expanded $\mathcal{L}_2$: with the new binary predicate $=$ to show when two constants are essentially the same despite being written with different letters
- Included the final set of rules for natural deduction to accommodate $=$
- Could now make numerical claims
This completes everything you need to know about first-order logic (more on this later), sometimes referred to as predicate calculus.
Part 2: Introduction to Metatheory
What we've covered before gives us a pretty reliable way to analyze English arguments, which philosophers really want to make sure they aren't tripping over themselves when discussing and debating ideas. But there are a whole host of patterns and results within logic itself that arguably have a bigger impact on the rest of science and deductive reasoning.
For example, consider the following theorem:
Deduction Theorem: $\Gamma, \Psi \vDash \Phi$ if and only if $\Gamma \vDash \Psi \rightarrow \Phi$.
By thinking through the definitions and terms we are working with, we can treat this almost as we would a mathematical theorem, and prove it analytically.
Proof: If $\Gamma, \Psi \vDash \Phi$, then by consistency (and definition of entailment), $\Gamma, \Psi, \neg \Phi \vDash $. Note that ony whenever the set $\{\Psi, \neg \Phi\}$ is satisfied, so is $\Psi \wedge \neg \Phi$. So we can rewrite our sequent as an equivalent one as $\Gamma, \Psi \wedge \neg \Phi \vDash$. By logical equivalence, then $\Gamma, \neg(\Psi \rightarrow \Phi) \vDash $. Then by consistency again, we arrive at $\Gamma \vDash \Psi \rightarrow \Phi$. $\blacksquare$
We are able to determine a result about arguments in general. We don't know what our premises and conclusion are, yet we can still make substantive claims regarding logical arguments of that form.
Here is another simple example that is commonly used all throughout science and math:
Contraposition: $\Phi \vDash \Psi$ if and only if $\neg \Psi \vDash \neg \Phi$.
"If it is Monday, then I have math class. So if I don't have math class, it certainly cannot be Monday." That is the general idea of argument by contraposition: if we know what premise entails a conclusion, and we don't observe the conclusion, the premise must not be fulfilled either.
Proof: Suppose $|\neg \Psi|_A = T$. Then $|\Psi|_A = F$. Since $\Phi \vDash \Psi$, then $|\Phi|_A = F$ too since if it didn't we would break our assumption of enatilment. Thus $|\neg \Phi|_A = T$. We made no assumptions about the structure $A$, and thus found whenever $|\neg \Psi|_A = T$, then also $|\neg \Phi|_A = T$. By the definition of entailment, $\neg \Psi \vDash \neg \Phi$.
We've already proven two useful theorems! Now, we will develop and practice using more tools to argue with logic as its own field of study rather than just an auxiliary field to other sciences.
Principle of Mathematical Induction
The major tool we will need is induction. For a hypothesis $\Phi$, the Principle of Mathematical Induction (PMI) is usually stated as:
The common analogy is with dominoes: if you knock over a starting domino (show hypothesis $\Phi$ works for integer like 0), and can prove that each domino will knock over the next domino (i.e. the hypothesis holding for $\Phi(n)$ implies the hypothesis holds for $\Phi(n+1)$), then you can infer that all the dominoes will fall over eventually (the hypothesis holds for all integers $\forall n \Phi(n)$).
Here is a classic example: we will show the formula for the sum of the first $n$ integers is $\sum_{k=1}^n k = \frac{n(n+1)}{2}$.
Base Case: The formula holds for $n=1$ since $\sum_{k=1}^1 k = 1 = \frac{1(1+1)}{2}$.
Inductive Hypothesis: Let's assume our formula works for the first $n$ integers. We want to show that it holds for case $n+1$: $\sum_{k=1}^{n+1} k = \sum_{k=1}^{n} k + (n+1)$. By our assumption, we can reduce this to $\frac{n(n+1)}{2} + n+1$. Simplifying further,
Which is precisely the formula our hypothesis predicted. So by the PMI, for all $n$, $\sum_{k=1}^n k = \frac{n(n+1)}{2}$.
Those who are more familiar with math will have seen examples of induction everywhere, and it is quite good for proving theorems and claims that naturally divide into these cases-by-integers.
One drawback of induction is that it does not tell you how you get your hypothesis to begin with. That usually requires trial-and-error with a strong intuition, but once you have it, induction gives a relatively straightforward way of proving your claim (if it is right).
The formulation above is sometimes referred to as weak induction. The alternative is strong induction:
Sometimes you need more cases besides just $\Phi(n)$ to prove $\Phi(n+1)$, so strong induction is a way to justify that. Despite the names, the weak and strong forms of induction are equivalent, so we can use either whenever.
With induction in hand, we can now start proving results within logic.
Example: Any $\mathcal{L}_1$ sentence $\Phi$ that only uses the connective $\leftrightarrow$ is not a contradiction i.e. there's a structure $A$ in which $|\Phi|_A = T$.
Proof: We will show this by giving a specific structure that $\Phi$ is true, and proving it holds via induction. I propose the structure $A$ where all sentence letters in $\Phi$ are assigned true. That is $\forall \alpha \in \textrm{SenLett}(\Phi) \ |\alpha|_A = T$.
Base Case: The simplest possible sentence using just $\leftrightarrow$ is the one not using it at all: a sentence letter. So if $\Phi$ is a sentence letter, by construction of our structure, $|\Phi|_A = T$.
Inductive Hypothesis: We'll induct on the complexity of $\Phi$. So let's build up $\Phi$ from "simpler" sentences; $\Phi = \Psi_1 \leftrightarrow \Psi_2$ where $\Psi_1, \Psi_2$ are both subsentences only containing $\leftrightarrow$. Remember, we have defined our structure $A$ such that $\forall \alpha \in \textrm{SenLett}(\Phi) \ |\alpha|_A = T$. Since $\Psi_1,\Psi_2$ build up $\Phi$, it should be clear that $\textrm{SenLett}(\Psi_{1,2}) \subseteq \textrm{SenLett}(\Phi)$. Then, by our structure, $\forall \alpha \in \textrm{SenLett}(\Psi_{1,2}) \ |\alpha|_A = T$. By our inductive hypothesis then, $|\Psi_1|_A = |\Psi_2|_A = T$, since they are $\mathcal{L}_1$ sentences that only use $\leftrightarrow$. By the truth table for $\leftrightarrow$, $|\Phi|_A = T$. $\blacksquare$
So for all sentences that only use $\leftrightarrow$, there is a structure in which it is true, and hence it is not a contradiction.
Induction naturally lends itself to proofs that are divided by integer cases, and we leveraged that by ascribing a natural number to a sentence via its complexity. Also note we used the strong form of induction here, since we don't actually know the complexity of $\Psi_1$ or $\Psi_2$, only that they are less complex than the inductive hypothesis necessitates. Here are some more formal definitions of what was used above, and others that will be helpful later:
- $\textrm{NConn}(\Phi)$: The number of occurrences of connectives in $\Phi$. We also define this as the complexity of $\Phi$, as it characterizes how "deep" subsentences go.
- $\textrm{Conn}(\Phi)$: The set of connectives used in $\Phi$; $\textrm{NConn}$ counts tokens, while $\textrm{Conn}$ counts types.
- $\textrm{SenLett}(\Phi)$: The set of sentence letters in $\Phi$.
- $\textrm{Atoms}(\Phi)$: The set of atomic objects in our language.
In general, $\textrm{Atoms}(\Phi) = \textrm{SenLett}(\Phi)$ for $\mathcal{L}_1$, but sometimes we will consider convenient extensions of $\mathcal{L}_1$. For one, it's sometimes useful to have a symbol for tautologies $\top$ and contradictions $\bot$. Just for clarity, for all structures $A$, $|\top|_A = T$ and $|\bot|_A = F$. These are considered useful atoms in the extended language $\mathcal{L}_1^+$.
Here's another example of how induction can be applied to logic:
De Morgan's Laws: For sentences $\varphi_1, \varphi_2, \cdots, \varphi_n$,
For those who are familiar with some set theory, these are identical to how set intersections (equivalent to $\wedge$) and unions (equivalent to $\vee$) relate to each other with complements ($\neg$).
Base Case: It can easily be seen by truth tables, or verified with natural deduction that $\neg(\varphi_1 \wedge \varphi_2) \equiv \neg\varphi_1 \vee \neg\varphi_2$ (even in English, it can be seen to be fairly reasonable).
Inductive Hypothesis: Assume this holds for $n$ sentences. Then:
The first equivalence is given by the case for 2 sentences, and the last is given by the case for $n$ sentences by the inductive hypothesis. The second law follows similarly. $\blacksquare$
The last immediate example we'll look at is a simple, yet important lemma.
Relevance Lemma: Suppose for two structures $A$ and $B$, $\forall \alpha \in \ \textrm{Atoms}(\Phi)$ we have it such that $|\alpha|_A = |\alpha|_B$. Then $|\Phi|_A = |\Phi|_B$.
The idea is that the only information pertinent to a logical sentence is what it looks like at the "lowest level"; only the sentence letters in $\Phi$ are what affect its truth value, and nothing else is necessary.
Proof: We'll follow similarly before by inducting on the complexity of $\Phi$.
Base Case: The simplest sentence $\Phi$ can be is a sentence letter. Then by the definition of structures, clearly $|\Phi|_A = |\Phi|_B$. In the case of $\mathcal{L}_1^+$, $\Phi$ can be $\top$ or $\bot$, but since their semantics are fixed for any structure, the claim still holds.
Inductive Hypothesis: Say this holds for sentences of complexity less than or equal to $n$. Now let $\Phi$ be a sentence of complexity $n+1$ i.e. $\textrm{NConn}(\Phi) = n+1$. Then $\Phi$ is of the form $\neg \Psi_1$, $\Psi_1 \wedge \Psi_2$, $\Psi_1 \vee \Psi_2$, $\Psi_1 \rightarrow \Psi_2$, or $\Psi_1 \leftrightarrow \Psi_2$ where $\textrm{NConn}(\Psi_{1,2}) \leq n$ and $\textrm{NConn}(\Psi_1) + \textrm{NConn}(\Psi_2) = n + 1$. If structures $A$ and $B$ agree on the values of the atoms of $\Phi$, they agree on the atoms of $\Psi_1$ and $\Psi_2$. By the inductive hypothesis, $|\Psi_1|_A = |\Psi_2|_B$. Since the truth value of $\Phi$ is fixed by the truth value of $\Psi_{1,2}$, then in all the cases, by their respective truth tables, $|\Phi|_A = |\Phi|_B$. $\blacksquare$
The Relevance Lemma essentially gives us a way of justifying finite truth tables; the reason why we know the sentence $P \wedge Q$ only depends on the truth values for $P$ and $Q$ is precisely because of the Relevance Lemma; so long as two structures agree on the value of $P$ and $Q$, they will agree on $P \wedge Q$ regardless of what the other sentence letters are assigned. It seems like an obvious fact, but is one that needs to be proven anyway.
Induction, especially on the complexity of sentences, will be a key tool in future results.
Truth Functions
For future convenience, we'll introduce the idea of a truth function. Just as you'd imagine, truth functions are like the typical function in math that takes some amount of inputs and spits out a single output. We thus define a truth function as a function $f: \{T,F\}^n \rightarrow \{T,F\}$. We have already seen some simple truth functions in the form of connectives. For example, $\wedge$ has the truth function such that $f_\wedge(T,F) = F$; if you connect a true sentence letter with a false sentence letter by $\wedge$, we get a more complex sentence that evaluates to false.
This leads to the natural idea of sentences expressing truth functions. We say a sentence $\Phi$ expresses a truth function $f$ iff the sentence letters $P_1,\cdots,P_n$ occur in $\Phi$, and $f(|P_1|_A, \cdots, |P_n|_A) = |\Phi|_A$.
Substitution
Earlier we discussed substitution briefly in the context of constants and variables with $\forall$ and $\exists$ and their proof rules. We can generalize substitution even further:
Definition: For a set of sentences $\Gamma$, $\Gamma[\varphi/S]$ is the uniform subsitution of the sentence $\varphi$ for the sentence letter $S$ in every sentence in $\Gamma$. If $S$ does not occur at all in $\Gamma$, then $\Gamma[\varphi/S] = \Gamma$.
For example, if we have the sentence $\Phi = P \rightarrow (Q \vee R) \wedge P$, then with substitution, $\Phi[(R \leftrightarrow \neg Q) / P] = (R \leftrightarrow \neg Q) \rightarrow (Q \vee R) \wedge (R \leftrightarrow \neg Q)$. This applies for sets of sentences as described above.
We then have the following theorem:
Substitution Theorem: If $\Gamma \vDash \Phi$, then $\Gamma[\varphi/S] \vDash \Phi[\varphi/S]$.
Which should sort of make sense; we've been focusing on the validity of argument as something intrinsic to the structure of the argument, as opposed to having anything to do with the specific sentences. So exchanging sentences with another in an argument should be no issue, even if the sentences are more complicated. We'll first prove a helpful lemma:
Substitution Lemma: For a sentence $\Psi$, sentence letter $X$, and a structure $A$, we define a new substitution structure $A_{\Psi/X}$ as follows:
That is, the structure keeps all sentence letters fixed, UNLESS it is $X$, which we assign the value of $\Psi$. Then for all sentences $\Phi$, we have $|\Phi[\Psi/X]|_A = |\Phi|_{A_{\Psi/X}}$.
Proof: We'll do this by induction on the complexity of $\Phi$ as usual.
Base Case: Simplest sentence is a sentence letter. Then by construction of $A_{\Psi/X}$, $|\Phi|_{A_{\Psi/X}} = |\Phi[\Psi/X]|_A$.
Inductive Hypothesis: Suppose this holds for sentences of complexity $n$. Let $\Phi$ be of complexity $n+1$. Then $\Phi$ is of the form $\neg \delta_1$, $\delta_1 \wedge \delta_2$, $\delta_1 \vee \delta_2$, $\delta_1 \rightarrow \delta_2$, or $\delta_1 \leftrightarrow \delta_2$ where $\textrm{NConn}(\delta_{1,2}) \leq n$ and $\textrm{NConn}(\delta_1) + \textrm{NConn}(\delta_2) = n + 1$. We can then check this by each case.
$\underline{\Phi = \neg \delta}$: $|\Phi|_{A_{\Psi/X}} = |\neg \delta|_{A_{\Psi/X}} = \color{red}{f_{\neg}(|\delta|_{A_{\Psi/X}}) = f_{\neg}(|\delta[\Psi/X]|_A)} = |\neg \delta[\Psi/X]|_A = |\Phi[\Psi/X]|_A$
$\underline{\Phi = \delta_1 \wedge \delta_2}$: $ \begin{align} |\Phi|_{A_{\Psi/X}} = |\delta_1 \wedge \delta_2|_{A_{\Psi/X}} = \color{red}{f_{\wedge}(|\delta_1|_{A_{\Psi/X}}, |\delta_2|_{A_{\Psi/X}})} \ & \color{red}{= f_{\wedge}(|\delta_1[\Psi/X]|_{A}, |\delta_2[\Psi/X]|_{A})} \\ & = |\delta_1[\Psi/X] \wedge \delta_2[\Psi/X]|_A \\ & = |(\delta_1 \wedge \delta_2)[\Psi/X]|_A \\ & = |\Phi[\Psi/X]|_A \end{align} $
The equality in red is given by the inductive hypothesis, and the rest by definitions of the connectives' truth functions and substitution. The other cases are all identical. $\blacksquare$
We can now prove the Substitution Theorem.
Proof: Suppose for contradiction that $\Gamma \vDash \Phi$ while $\Gamma[\varphi/S] \nvDash \Phi[\varphi/S]$. That is, there is a structure where $A$ where $\forall \gamma \in \Gamma \ |\gamma[\varphi/S]|_A = T$ while $|\Phi[\varphi/S]|_A = F$.
By the Substitution Lemma, there is another structure $B$ where $|\gamma|_B = |\gamma[\varphi/S]|_A = T$ and $|\Phi|_B = |\Phi[\varphi/S]|_A = F$. But that contradicts our original assumption that $\Gamma \vDash \Phi$. So it must be the case that $\Gamma[\varphi/S] \vDash \Phi[\varphi/S]$. $\blacksquare$
Disjunctive Normal Form and Expressive Adequacy
While we have the connectives $\wedge,\vee,\neg,\rightarrow,\leftrightarrow$, there's a natural question as to whether or not we need all of them.
Disjunctive Normal Form
Consider the following sentence: $\neg((P \wedge Q \rightarrow R) \leftrightarrow \neg Q)$. Let's write out the truth table for this sentence.
This sentence is fairly compact, but also not very readable. We can instead rewrite this sentence into something slightly longer, but logically equivalent that is indicative of what this sentence is saying.
Notice that this sentence is true if and only if one of the three types of structures are in use:
- $P,Q,R$ are true
- $P$ is false (or $\neg P$ is true), and $Q,R$ are true
- $P$ is false (or $\neg P$ is true), $Q$ is true, and $R$ is false (or $\neg R$ is true)
These correspond to the highlighted rows in the truth table. We can express these truth conditions of the sentence easily then by reading off each condition:
Whenever the red structure is in use, then our original sentence is true. Likewise, the first disjunct in the above sentence is also true, making the whole sentence true by the truth table for $\vee$. Similarly, when the blue or green structures are in use, our original sentence is true and so is our new sentence made of just $\neg$, $\wedge$, and $\vee$. And when none of those structures are used, then our original sentence is false, and since our new sentence is made from only the conditions that make our original sentence true, it too would be false. Since these two sentences are true in the same structures and false in all the same structures, these sentences are logically equivalent.
We call this second sentence the disjunctive normal form of the original sentence.
Definition: A sentence is in disjunctive normal form (DNF) if it only uses connectives from the set $\{\neg, \wedge, \vee \}$, and that $\vee$ never occurs in the scope of $\neg$ or $\wedge$, and $\wedge$ never occurs in the scope of $\neg$. Informally, a sentence is in DNF if it is a conjunction of disjunctions of sentence letters or their negations.
Our above method gives a constructive way on how to convert sentences into DNF using truth tables. A more formal version of the proof specifying structures is given in Eagle's Elements of Deductive Logic, but the idea remains the same even if obscured by notation. A sentence $\Phi$ can be written in DNF by writing
where each Case is the listing of the truth conditions needed given by the sentence letters.
The alternative to DNF is the conjunctive nomal form (CNF), where you can write a logically equivalent sentence using a conjunction of disjunctions of sentence letters and or their negations. The proof that any sentence can be written in CNF can be done similarly to the proof of DNF. The idea is a sentence $\Phi$ is true if and only if none of the structures that make it false are in use.
But we also can use De Morgan's Laws and the existence of DNF to prove the existence of CNF much quicker. First, write $\neg \Phi$ in DNF: $\neg \Phi \equiv \bigvee_{n=1}^m (\bigwedge_{i=1}^k \mathscr{P}_i)$ where $\mathscr{P}_i$ is a sentence letter or its negation. This would say that there are $k$ sentence letters in $\neg \Phi$, and that you only need $m$ disjuncts to express it. But, since $\neg \neg \Phi \equiv \Phi$, we can negate $\neg \Phi$ in DNF to get $\Phi$ in CNF:
which is precisely in CNF, with $m$ conjuncts and all the sentence letters and their negations negated.
Expressive Adequacy
We have seen above that we can convert any sentence into a logically equivalent one using only $\neg$, $\wedge$, and $\vee$. However, note the only thing we really needed was the truth table of a sentence, not the sentence itself. So if we outline any truth function via a truth table, we can find a sentence in DNF that expresses that truth function.
So we say that the set of connectives $\{\neg, \wedge, \vee \}$ is expressively adequate: any truth function can be expressed by a sentence using exclusively the connectives $\{\neg, \wedge, \vee \}$. In other words, the truth functions of $\{\neg, \wedge, \vee \}$ can make any other truth function under composition with each other. We proved that with the existence of DNF.
Then, in a way, we have some redundant connectives in $\mathcal{L_1}$: $\rightarrow$ and $\leftrightarrow$ can be expressed using $\{\neg, \wedge, \vee \}$.
Of course, it's much more convenient to use $\rightarrow$ and $\leftrightarrow$ than their equivalent forms, but in a way, they are just that—a convenience.
But we can do better. We know from De Morgan's Laws:
So even $\wedge$ and $\vee$ is redundant; you only need one of them with negation to express the other.
So we have two small expressively adequate sets already with $\{\neg, \vee\}$ and $\{\neg, \wedge\}$, but there are many others, such as $\{\neg, \rightarrow \}$ and $\{ \rightarrow, \bot \}$. There are even single connectives that are expressively adequate. Consider the connectives with the following truth tables:
$\uparrow$ is sometimes called nand (as in not/negated-and) while $\downarrow$ is nor (not-or). Since we know $\{\neg, \wedge \}$ is expressively adequate, and that
so $\{\uparrow \}$ can express the truth functions of the expressively adequate connective set $\{\neg, \wedge \}$. Thus, $\{\uparrow \} $ is expressively adequate.
Here are some good exercises to try and fully wrap your head around expressive adequacy:
- Show that $\{\downarrow \}$ is expressively adequate as well (hint: try to write another expressively adequate set in terms of just $\downarrow$).
- Show $\uparrow$ and $\downarrow$ are the only 2-place connectives that are expressively adequate by themselves.
- Consider the 3-place connective $\square(\Phi, \Psi, \Delta)$ which is true iff $\Phi,\Psi,\Delta$ are all false. Show $\{\square\}$ is expressively adequate.
- Show $\{\neg\}$ is not expressively adequate (hint: how many inputs can a sentence only using $\neg$ have?)
- Show $\{\vee, \wedge, \rightarrow, \leftrightarrow\}$ is not expressively adequate (hint: find a specific truth function it cannot express).
- Consider the new connective $\leftrightarrow^*$ with the following truth table:
$ \begin{array}{c|c|c} P & Q & (P \leftrightarrow^* Q) \\ \hline T & T & F \\ T & F & T \\ F & T & T \\ F & F & F \\ \end{array} $ Show $\{\leftrightarrow, \leftrightarrow^*\}$ is not expressively adequate.
Duality
We have seen many times that there's a natural interplay between between $\wedge$ and $\vee$ with patterns of negation with De Morgan's Laws, and as well as between $\forall$ and $\exists$. Even in English, we see this mixing of "internal" and "external" negations; "already outside" means the same thing as "not still inside", so "already" and "still" act in this "dual" manner, similar to $\wedge$ and $\vee$.
We can formalize logical duality, but we first will introduce a new, convenient extension to $\mathcal{L}_1^+$, appropriately called $\mathcal{L}_1^{++}$. This language is exactly like $\mathcal{L_1}^+$, but with the addition of generalized connectives; for each $n$-place truth function $f$, there is a unique $n$-place connective $c$ that is associated with $f$ i.e. that would express it with $n$ sentence letters.
Something else worth noting that I've avoided for consistency is that sometimes it's useful to represent $T$ with 1 and $F$ with 0, so we can do basic arithmetic to simplify our manipulation of truth values. For example, $|\neg P|_A = 1 - |P|_A$, or with $\wedge$, $|P \wedge Q|_A = |P|_A \cdot |Q|_A$.
Definition (Dual of a Connective): Let $c$ be an $n$-place connective with associated truth function $f_c$. The dual connective $c^*$ is the connective with the associated truth function $f_{c^*}$ defined as:
for all truth values $t_1,t_2,\cdots,t_n$.
In essence, the dual connective is defined by this relation of internal and external negations. In our discussion of expressive adequacy, the final problem I wrote at the end used $\leftrightarrow^{*}$, the dual of $\leftrightarrow$. For a more visual definition, the dual of a connective $c^*$ is obtained by flipping every occurrence of $T$ to $F$ and $F$ to $T$ in the truth table for $c$. If we look at $\wedge$, then
We see then that $\wedge^*$ has the exact same truth table for $\vee$, and conclude they are duals. If we do the same for $\vee$, we would see that $\vee^*$ has the same truth table for $\wedge$, and that leads us to our first observation.
Claim: For all $\mathcal{L}_1^{++}$ connectives, $c^{**} = c$.
Proof:
Since these associated truth functions are unique to each connective, we've shown $c^{**} = c$. $\blacksquare$
Connective duals are the heart of this topic, so with that solidified, we are now in a position to define other forms of duality:
Definition (Generalized Duality):
- The dual of a sentence is given recursively: if $\Phi$ is a sentence letter, then $\Phi^{*} = \Phi$, and if $\Phi = c(\varphi_1, \cdots, \varphi_n)$, then $\Phi^{*} = (c(\varphi_1, \cdots, \varphi_n))^{*} = c^{*}(\varphi_1^{*}, \cdots, \varphi_n^{*})$
- Let $T^* = F$ and $F^* = T$. The dual of a structure $A^{*}$ is defined by flipping the truth values of all sentence letters in $A$, i.e. $|\alpha|_{A^*} = (|\alpha|_A)^* = 1 - |\alpha|_A$ for all sentence letters $\alpha$
We can now prove another adjacent lemma as before.
Claim: For all $\mathcal{L}_1^{++}$ sentences, $\Phi^{**} = \Phi$.
Proof: Induct on the complexity of $\Phi$.
Base Case: If $\Phi$ is a sentence letter, then $\Phi^{**} = (\Phi^*)^* = \Phi^* = \Phi$.
Inductive Hypothesis: Suppose this holds for sentences of complexity $n$. Let $c$ be the highest scope connective of $\Phi$ i.e. $\Phi = c(\varphi_1, \varphi_2, \cdots, \varphi_n)$ with $\textrm{NConn}(\varphi_i) \leq n$. Then
It's worth mentioning that outside of $\mathcal{L}_1^{++}$, it might not be the case that $\Phi^{**} = \Phi$ since we don't have this nice general connective $c$ to work with. But, it will still be logically equivalent; they may not look the same in other languages (as in use the exact same characters in the exact same order), but certainly $\Phi^{**} \equiv \Phi$.
With all of this in place, we now have our first major result:
Duality Lemma: For all sentences, $|\Phi^*|_A + |\Phi|_{A^*} = 1$. In other words, $|\Phi^*|_A = |\neg\Phi|_{A^*}$
Proof: Induct on the complexity of $\Phi$.
Base Case: If $\Phi$ is a sentence letter, then $|\Phi^{*}|_A = |\Phi|_A = 1 - |\Phi|_{A^*}$
Inductive Hypothesis: Suppose this holds for sentences of complexity $n$. Let $c$ be the highest scope connective of $\Phi$ i.e. $\Phi = c(\varphi_1, \varphi_2, \cdots, \varphi_n)$ with $\textrm{NConn}(\varphi_i) \leq n$. Then
This lemma comes with a very nice consequence:
Duality Theorem: If $\Phi \vDash \Psi$, then $\Psi^* \vDash \Phi^*$.
Proof: Say $|\Psi^*|_A = 1$. Then by the Duality Lemma, $|\Psi|_{A^*} = 0$. Since $\Phi \vDash \Psi$, then $|\Phi|_{A^*} = 0$. By the Duality Lemma again, $|\Phi^*|_A = 1$. So in any structure where $|\Psi^*|_A = 1$, $|\Phi^*|_A = 1$. In other words, $\Psi^* \vDash \Phi^*$.
Some other interesting ideas to consider:
- We proved earlier that $c^{**} = c$, but that does not rule out the possibility that there are connectives such that $c^* = c$. For example, $\neg$ is self-dual as $\neg^* = \neg$. Can you find any other self-dual connectives?
- Having shown $\wedge$ and $\vee$ as duals, this gives us a nice informal way to explain why $\forall$ and $\exists$ are duals too (remember, $\forall x Px \equiv \neg \exists x \neg Px$). Informally, $\forall x Px$ sort of expresses $\bigwedge_{\tau \in C} P\tau$ which ranges over all constants $C$ (while accurate, it is not a strictly good way of defining $\forall x Px$ as sentences cannot be of infinite length). Similarly, $\exists x Px$ is sort of equivalent to $\bigvee_{\tau\in C} P\tau$. So given the duality of $\wedge$ and $\vee$, perhaps it is not that surprising that $\forall$ and $\exists$ are duals of each other too.
- The Duality Theorem applies to only single sentences entailing other sentences, but what about sets of sentences? We can make a modified version for entailment between sets: we say $\Gamma \vDash \Sigma$ if when all sentences of $\Gamma$ are true, at least one sentence of $\Sigma$ is true. We can then also define $\Gamma^* = \{\gamma^* \ | \ \gamma \in \Gamma \}$ i.e. the dual of a set of sentences is the set of all dual sentences in the set. Then we can also prove in a similar manner if $\Gamma \vDash \Sigma$, then $\Sigma^* \vDash \Gamma^*$.
Part 3: Soundness and Completeness
The previous section was an exploration into how we are able to analyze logic in a very robust and formal way akin to the way we do so in math. And to be fair, it did start to feel like we were doing math after a certain point; we were manipulating sentences and structures in a fairly abstract way, while interesting, did not always have a direct appeal to why we were cared about those topics outside of curious questions. We now return back to some more concrete motivations, as we now have the methods to finally break down the two key theorems that make logic useful.
Soundness
As mentioned earlier, soundness is basically what makes proof systems and provability useful. As a reminder,
Soundness Theorem: If $\Gamma \vdash \Phi$, then $\Gamma \vDash \Phi$.
That is, for a given proof system, if it is sound, then it "preserves truth"; you wouldn't be able to prove something that is a non-sensical, bad argument. Soundness is arguably one of, if not, the most important quality we can have in a logical system. It's what allows us to know that for any right triangle the square of the shorter legs sum to the hypotenuse without having to check every right triangle. It's what allows us to know that $\sqrt{2}$ is irrational without having to check every possible fraction.
And the way you prove soundness is surprisingly easy.
Proof: We will prove this with induction, but instead of looking at the complexity of sentences, we will induct on the complexity of proofs; we will ascribe an integer to a proof to how many natural deduction rules it uses.
It's also worth noting here that our proof of soundness below only applies to natural deduction; we have to prove soundness for each proof system. We are working with Natural Deduction, so we will show those rules are sound, but if we use another proof system, say, Frege's propositional calculus, we would have to re-prove soundness (since we could just make up arbitrary proof rules that are not sound if we wanted).
Base Case: The simplest proof of "complexity 0" of $\Phi$ is from $\Phi$ itself $\Phi \vdash \Phi$; if you know $\Phi$, you certainly know $\Phi$ without needing to use any proof rules. Clearly $\Phi \vDash \Phi$ as any structure such that $|\Phi|_A = T$, that structure also assigns $|\Phi|_A = T$, establishing the base case.
Inductive Step: Now we will assume from premises $\Gamma$ that our proofs are sound, up until the last step. We will check for each of our Natural Deduction rules that they are sound.
$\underline{\wedge\textrm{-Intro:}}$ Suppose we have a proof of $\Psi_1$ from premises $\Pi_1$ (that is, $\Pi_1 \vdash \Psi_1$) and $\Psi_2$ from premises $\Pi_2$ (similarly $\Pi_2 \vdash \Psi_2$), we obtain a proof $\Psi_1 \wedge \Psi_2$ from an application of $\wedge\textrm{-Intro}$ (where $\Pi_1, \Pi_2 \subseteq \Gamma \ $). By our inductive hypothesis, $\Pi_1 \vDash \Psi_1$ and $\Pi_2 \vDash \Psi_2$. So, for any structure that satisfies $\Gamma$, that structure clearly satisfies $\Pi_1$ and $\Pi_2$ (as they come from $\Gamma \ $), and therefore also satisfies $\Psi_1$ and $\Psi_2$ (by the entailment derived from our inductive hypothesis). So $\Gamma \vDash \Psi_1$ and $\Gamma \vDash \Psi_2$. By the truth table for $\wedge$, we can see that $\Gamma \vDash \Psi_1 \wedge \Psi_2$.
$\underline{\wedge\textrm{-Elim:}}$ From a proof of $\Psi_1 \wedge \Psi_2$ on premises $\Gamma$ ($ \ \Gamma \vdash \Psi_1 \wedge \Psi_2$), we obtain a proof of $\Psi_1$ (or $\Psi_2$) using $\wedge\textrm{-Elim}$. By our inductive hypothesis, $\Gamma \vDash \Psi_1 \wedge \Psi_2$. By the truth table for $\wedge$, $\Psi_1 \wedge \Psi_2$ is true iff $\Psi_1$ and $\Psi_2$ are true, so we can conclude $\Gamma \vDash \Psi_1$ and $\Gamma \vDash \Psi_2$.
This is the basic idea of proving soundness: use our knowledge of semantics and definitions to show our final entailment. Sometimes it is just a matter of writing out what feels obvious, but some might require some more background knowledge or tricks.
$\underline{\textrm{→-Intro:}}$ From a proof of $\Phi$ on premises $\Gamma \cup \{\Psi\}$, get a proof $\Gamma \vdash \Psi \rightarrow \Phi$ with $\textrm{→-Intro}$ (discharging $\Psi$ at the end). From the inductive hypothesis $\Gamma, \Psi \vDash \Phi$. By the Deduction Theorem, $\Gamma \vDash \Psi \rightarrow \Phi$.
$\underline{\textrm{→-Elim:}}$ From a proof of $\Psi$ on premises $\Pi_1$ and another proof of $\Psi \rightarrow \Phi$ from premises $\Pi_2$, obtain a proof of $\Phi$ via $\textrm{→-Elim}$ (where $\Pi_1, \Pi_2 \subseteq \Gamma \ $). By the inductive hypothesis, $\Gamma \vDash \Psi$ and $\Gamma \vDash \Psi \rightarrow \Phi$. By the truth table for $\rightarrow$, whenever $\Gamma$ is satisfied, $\Phi$ must also be satisfied. Thus, $\Gamma \vDash \Phi$.
The other cases for $\neg$, $\vee$, and $\leftrightarrow$ are all very similar (but do know they are in fact sound). $ \ \blacksquare$
Soundness of $\mathcal{L}_2$
The above proof shows the natural deduction proof system is sound in $\mathcal{L}_1$, but we've moved on past to bigger and better things. To show natural deduction is sound in $\mathcal{L}_2$, we only need to show the 4 new rules are sound: $\forall\textrm{-Intro}$, $\forall\textrm{-Elim}$, $\exists\textrm{-Intro}$, and $\exists\textrm{-Elim}$.
I won't go through them in detail (because I this post is long enough and I don't want to type them out), but the proof idea is exactly the same as it was for $\mathcal{L}_1$. Here's a rough sketch of the results one could show to deduce soundness of $\mathcal{L}_2$ (starter proofs can be found in Elements of Deductive Logic):
- Substitution of Co-Designating Terms: Let $\tau_1$ and $\tau_2$ be constants/variables, and $\varphi[\tau_2/\tau_1]$ is the formula of replacing free occurrences of $\tau_1$ by $\tau_2$ where none of these instances fall under $\forall \tau_2$ or $\exists \tau_2$ (constants occur freely vacuously). Then for any structure $A$ and variable assignment $\alpha$ where $|\tau_1|_A^\alpha = |\tau_2|_A^\alpha$, then $|\varphi|_A^\alpha = |\varphi[\tau_2/\tau_1]|_A^\alpha$ (show with induction on the length of formulae).
- This basically says that if two constants/variables stand for the same thing, they are interchangeable in that variable assignment.
- With substitution of co-designating terms and the satisfaction rules for $\forall$ and $\exists$, show the following sequents are correct:
- $\Phi[t/v] \vDash \exists v \Phi$
- $\forall v \Phi \vDash \Phi[t/v]$
- If $\Gamma, \Phi[t/v] \vDash \Psi$, then $\Gamma, \exists v \Phi \vDash \Psi$ where the constant $t$ does not occur in $\Gamma, \Phi, \Psi$
- If $\Gamma \vDash \Phi[t/v]$, then $\Gamma \vDash \forall v \Phi$ where constant $t$ does not occur in $\Gamma, \Phi$
- Use those sequents to complete the Soundess Theorem for $\forall$ and $\exists$ in the inductive steps of the proof.
Completeness
We have shown soundness, meaning anything that we do prove is a good argument. But we haven't really given a method of showing how to prove things; proofs in natural deduction—in math even—often rely on having a good intuition of the problem at hand that can be formalized into rigorous logic. For example, look at the following claim and proof:
Claim: There exists irrational numbers $a$ and $b$ such that $a^b$ is rational.
Proof: Consider the number $\sqrt{2}^\sqrt{2}$.
- If this is rational, we're done.
- If this is irrational, then consider the number $(\sqrt{2}^\sqrt{2})^\sqrt{2} = \sqrt{2}^2 = 2$, which is rational, and we are done.
Never once did we actually deduce the rationality of $\sqrt{2}^\sqrt{2}$, but by exhausting the possible cases, it doesn't matter since every possibility leads to a conclusion that proves our claim. $ \ \blacksquare$
To independently think of the above proof, one would have to just be comfortable and familiar with exponents, since it really just abused the fact how exponenets combine to create a possible number that satisfies the claim. Moreover, the above proof used the implicit, extra premise that all real numbers are either rational or irrational. This might be a tautology that can be proven under what one assumes about the real numbers, but that would still need to be shown (since not everyone necessarily takes this for granted). All together, this proof requires a lot of creativiity to not only think of the individual, relevant facts, but to string them together too.
What am I getting at, though? Since there is no algorithm or method to go about proofs, we have no good way to determine if we can prove something until we have proved it. When something has not been proven, though, we don't just give up; mathematicians and scientists keep searching for new techniques and evidence in the hopes of proving or disproving a theorem. But there's a key word there: "hope". We don't actually know if what we are trying to prove, actually is provable! We don't know if we are wasting our time away on a Sisyphean quest with no end.
Ideally, we want to be working in a complete logical system, that is:
Completeness Theorem: If $\Gamma \vDash \Phi$, then $\Gamma \vdash \Phi$.
This is the converse of soundness, and would be a very convenient property of our logic to have, since it would mean there are no "unjustified" truths; all arguments would have a chain of causal reasoning in our deductive system that allow us to show its validity.
Some of you may have heard of completeness over soundness before for a couple of reasons: 1) soundness is a fairly intuitive property many of us just trust, as much of logic can be readily thought out to seem to make sense; but more likely 2) Gödel's incompleteness theorems are among the most celebrated and frustrating results of modern math that have infiltrated the highest ranks of science legends. Ultimately, they culminate many decades of the development of logic and putting to rest, arguably the most fundamental question in math: can we know everything? The ultimate answer is no, leaving us with many theorems in math that might be logically true, but just unprovable from our axioms. As of now, over 10 trillion non-trivial zeroes of the Riemann hypothesis have been verified, yet a concrete, irrefutable proof of this 160 year old problem still eludes us, and incompleteness forces us to wonder if there might not be one at all (but if the Riemann hypothesis is false, then it is provably false according to Robin's theorem!).
But that's going a bit too far off the beaten path. Fortunately for us, $\mathcal{L}_1$, $\mathcal{L}_2$, and $\mathcal{L}_=$ are all complete logics, and the rest of this section will be to show that, starting with $\mathcal{L}_1$.
Having a complete system is desirable for a few reasons. Having all theorems be provable is of course nice, but completeness also allows us to connect a lot of dots between semantics and proofs as we would expect. Earlier we mentioned the idea of ND-consistency. In a sound and complete system (which ND is), it turns out syntactic consistency is equivalent to semantic consistency (or satisfiability):
Claim: $\Gamma$ is ND-consistent iff it is satisfiable.
Proof:
$(\Rightarrow)$ Suppose $\Gamma$ is ND-consistent. Then there is a sentence $\Phi$ such that $\Gamma \nvdash \Phi$. By completeness, $\Gamma \nvDash \Phi$. The only way an argument or sequent is invalid is if there is a structure $A$ such that $A \vDash \Gamma$ but $A \nvDash \Phi$. But then we have a structure such that $A \vDash \Gamma$, thus showing $\Gamma$ is satisfiable.
$(\Leftarrow)$ We'll prove the contrapositive i.e. we'll show that if $\Gamma$ is ND-inconsistent, then it is unsatisfiable. So say $\Gamma$ is ND-inconsistent, that is, $\Gamma \vdash \Phi$ for all sentences $\Phi$. By soundness, we have $\Gamma \vDash \Phi$ for all sentences $\Phi$. This includes contradictions, such as $\Phi = P \wedge \neg P$, and the only way $\Gamma$ could entail all sentences, including contradictions, would be if it was unsatisfiable.
From here on, I'll use consistent only to mean ND-consistent unless I specify otherwise, and use satisfiable for semantic consistency.
Deductive Completeness
Our ultimate goal is to prove completeness of a logical language. But first, we'll need to talk about the completeness of a set of sentences:
- Definition (Semantic Completeness): $\Gamma$ is semantically complete when for all sentences $\Phi$, either $\Gamma \vDash \Phi$ or $\Gamma \vDash \neg \Phi$ (or both)
- Definition (Deductive Completeness): $\Gamma$ is deductively complete when for all sentences $\Phi$, either $\Gamma \vdash \Phi$ or $\Gamma \vdash \neg \Phi$ (or both)
Semantically complete sets are like structures, ascribing truth values to all sentences when it is satisfied. Deductively complete sets act likewise but with proofs.
Combining ND-consistency and ND-completeness allows us to prove a very intuitive result about proofs:
Consistency and Completeness Lemma: Suppose $\Gamma \subseteq \textrm{Sen}(\mathcal{L}_1)$ is ND-consistent and -complete. Then for all sentences $\Phi,\Psi$:
- $\Gamma \vdash \neg \Phi$ iff $\Gamma \nvdash \Phi$
- $\Gamma \vdash \Phi \wedge \Psi$ iff $\Gamma \vdash \Phi$ and $\Gamma \vdash \Psi$
- $\Gamma \vdash \Phi \vee \Psi$ iff $\Gamma \vdash \Phi$ or $\Gamma \vdash \Psi$ (or both)
- $\Gamma \vdash \Phi \rightarrow \Psi$ iff $\Gamma \nvdash \Phi$ or $\Gamma \vdash \Psi$ (or both)
- $\Gamma \vdash \Phi \leftrightarrow \Psi$ iff $\Gamma \vdash \Phi$ and $\Gamma \vdash \Psi$, or $\Gamma \nvdash \Phi$ and $\Gamma \nvdash \Psi$
This lemma esentially allows us to formalize results about proofs in how we would expect them to act; it gives us a bridge that consistency and completeness are enough to show that proofs and derivability act like truth in a structure.
Proof: We'll just verify each case individually.
Case (i):
- $(\Rightarrow)$ Say $\Gamma \vdash \neg \Phi$. By its ND-consistency, $\Gamma \nvdash \Phi$.
- $(\Leftarrow)$ Say $\Gamma \nvdash \Phi$. By its ND-completeness, $\Gamma \vdash \neg \Phi$.
Case (ii):
- $(\Rightarrow)$ If $\Gamma \vdash \Phi \wedge \Psi$, then by $\wedge$-Elim, $\Gamma \vdash \Phi$ and $\Gamma \vdash \Psi$.
- $(\Leftarrow)$ If $\Gamma \vdash \Phi$ and $\Gamma \vdash \Psi$, we can combine these two proofs into one bigger proof by applying $\wedge$-Intro, netting us a proof of $\Gamma \vdash \Phi \wedge \Psi$.
Cases (iii), (iv), and (v) are all similar: look at the given proof we assume, and extend it via natural deduction to get the conclusion we want. $ \ \blacksquare$
Maximally Consistent Sets
The central idea that we'll use to prove the completeness of $\mathcal{L}_1$ is maximally consistent sets.
Definition (Maximally Consistent Sets): A set $\Gamma$ is maximally consistent (or maximally D-consistent with respect to a proof system $D$) when $\Gamma$ is ND-consistent, and if $\Gamma \cup \{\Phi \}$ is ND-consistent, then $\Phi \in \Gamma$.
We can think of maximally consistent sets as model universes, completely filled with as many rules (sentences) that determine the laws and facts of this universe without contradicting itself. One more sentence and $\Gamma$ would no longer be consistent.
Conveniently enough, maximally consistent sets hold the two properties we just discussed.
Maximally Consistent Sets Are Complete: If $\Gamma \subseteq \textrm{Sen}(\mathcal{L}_1)$ is maximally consistent, then it is ND-consistent and ND-complete.
Proof: By definition of maximal consistency, $\Gamma$ is ND-consistent.
Now suppose for a contradiction that $\Gamma$ was ND-incomplete, i.e. there's a sentence $\Phi$ such that $\Gamma \nvdash \Phi$ and $\Gamma \nvdash \neg \Phi$. Hence, I claim both $\Phi \in \Gamma$ and $\neg \Phi \in \Gamma$, making $\Gamma$ inconsistent and showing our assumption of its incompleteness incorrect. To show a sentence $\Psi \in \Gamma$, we can leverage the definition of maximal consistency that $\Gamma \cup \{\Psi \}$ is consistent.
- Consider for contradiction that $\Gamma \cup \{\neg \Phi \}$ is inconsistent. Then, it would prove everything, and in particular, it would also prove $\Gamma \cup \{\neg \Phi \} \vdash \Phi$. By $\neg$-Elim, we can see that also $\Gamma \vdash \Phi$ since $\neg \Phi$ can be discarded in that proof. But we already know that $\Gamma \nvdash \Phi$, so it must be that $\Gamma \cup \{\neg \Phi \}$ is consistent. By maximal consistency then, $\neg \Phi \in \Gamma$.
- Same argument as before, but with assuming $\Gamma \cup \{\Phi \}$ is inconsistent. Similarly we can conclude $\Phi \in \Gamma$.
Since $\{\Phi, \neg \Phi\} \subseteq \Gamma$, we have $\Gamma \vdash \Phi$ and $\Gamma \vdash \neg \Phi$ trivially, and thus with $\neg$-Elim, $\Gamma$ proves everything. Hence it is inconsistent, which contradicts that it is maximally consistent. Hence $\Gamma$ must be ND-complete. $ \ \blacksquare$
Another nice property of maximally consistent sets is that they provability and membership are equivalent in $\Gamma$.
Membership Lemma: If $\Gamma$ is maximally consistent, then $\Gamma \vdash \Phi$ iff $\Phi \in \Gamma$.
Proof:
- $(\Leftarrow)$ Clearly if $\Phi \in \Gamma$, then $\Gamma \vdash \Phi$ trivially.
- $(\Rightarrow)$ Since $\Gamma \vdash \Phi$, by the consistency of $\Gamma$, we also have $\Gamma \nvdash \neg \Phi$ (since if it proved both, then we would be able to prove any sentence with $\neg$-Elim). We want to show $\Phi \in \Gamma$, which would be true if $\Gamma \cup \{\Phi\}$ was consistent (by definition of a maximally consistent set). Say for a contradiction that $\Gamma \cup \{\Phi\}$ was inconsistent, that is, it proves everything. If it proves everything, in particular, it also proves $\Gamma \cup \{\Phi\} \vdash \neg \Phi$. But then also, $\Gamma \vdash \neg \Phi$, since by $\neg$-Intro, we can discard the premise $\Phi$ as an assumed premise that we do not actually need concretely. This contradicts the fact that $\Gamma \nvdash \neg \Phi$, so our assumption must be wrong. Therefore, $\Gamma \cup \{\Phi\}$ is consistent, and hence $\Phi \in \Gamma$ by definition of a maximally consistent set.
With these two lemmas in mind, we can now generalize membership for $\Gamma$ even broader:
Generalized Membership Lemma: Suppose $\Gamma \subseteq \textrm{Sen}(\mathcal{L}_1)$ is maximally consistent. Then for all sentences $\Phi,\Psi$:
- $\neg\Phi \in \Gamma$ iff $\Phi \notin \Gamma$
- $\Phi \wedge \Psi \in \Gamma$ iff $\Phi \in \Gamma$ and $\Psi \in \Gamma$
- $\Phi \vee \Psi \in \Gamma$ iff $\Phi \in \Gamma$ or $\Psi \in \Gamma$ (or both)
- $\Phi \rightarrow \Psi \in \Gamma$ iff $\Phi \notin \Gamma$ or $\Psi \in \Gamma$ (or both)
- $\Phi \leftrightarrow \Psi \in \Gamma$ iff $\Phi \in \Gamma$ and $\Psi \in \Gamma$, or $\Phi \notin \Gamma$ and $\Psi \notin \Gamma$
Proof: We've already done all the work in the previous lemmas. $\Gamma$ is maximally consistent, so it's ND-consistent and ND-complete. By the Consistency and Completeness Lemma, we have all those cases about provability true in $\Gamma$. By the Membership Lemma, we can replace all those proofs with clauses of membership. $ \ \blacksquare$
Now compare each of these cases of the Generalized Membership Lemma to what satisfaction looks in a structure. The relations are identical! This is the key property of maximally consistent sets: membership in $\Gamma$ acts like truth in an $\mathcal{L}_1$-structure. Likewise, we are able to not only make a maximally consistent set $\Gamma$, but also create a structure specifically tailored to satisfy $\Gamma$.
Constructing a Maximally Consistent Set
Maximally consistent sets are filled with as many sentences as possible while remaining consistent. So, if we wanted to make a maximally consistent set, we could just look at every sentence and see if we can add it to our bucket while remaining consistent.
Completeness Lemma 1: Suppose we have an ND-consistent set $\Gamma$. Then there is a maximally consistent set $\Gamma^{+}$ with $\Gamma \subseteq \Gamma^{+}$.
Proof: The idea is that there are a countably infinite number of sentence letters in $\mathcal{L}_1$, and therefore a countably infinite number of sentences in $\mathcal{L}_1$ too (the Cartesian product of two countably infinite sets is countably infinite). So we just go through all the possible sentences, add them to $\Gamma$ if preserves consistency, and at the end we obtain not just a consistent, but maximally consistent set.
Let $\textrm{Sen}(\mathcal{L}_1) = \{\Phi_0, \Phi_1, \Phi_2, \cdots\}$, and let $\Gamma_0 = \Gamma$. We then define the recursion
Then let $\Gamma^{+} = \bigcup_{n} \Gamma_n$. By construction, $\Gamma_n$ is consistent and $\Gamma_n \subseteq \Gamma^+$ for all $n$. Importantly, including $n=0$, so $\Gamma = \Gamma_0 \subseteq \Gamma^+$.
- First we show that $\Gamma^+$ is ND-consistent. Say it wasn't. Then $\Gamma^+$ proves every sentence, so $\Gamma^+ \vdash \varphi$ and $\Gamma^+ \vdash \neg \varphi$ for some sentence $\varphi$. Proofs must be finite (what would an infinite proof look like?), so we only need finite premises to prove these claims:
$\{\gamma_1, \gamma_2, \cdots, \gamma_m \} \vdash \varphi$ where $\{\gamma_1, \gamma_2, \cdots, \gamma_n \} \subseteq \Gamma^+$ $\{\delta_1, \delta_2, \cdots, \delta_n \} \vdash \neg\varphi$ where $\{\delta_1, \delta_2, \cdots, \delta_n \} \subseteq \Gamma^+$ Where $m$ and $n$ are some positive integers. Then, the finitely many sentences of $\{\gamma_1, \gamma_2, \cdots, \gamma_m \} \cup \{\delta_1, \delta_2, \cdots, \delta_n \}$ must have appeared somewhere in our listing of $\textrm{Sen}(\mathcal{L}_1)$ and thus must all have been added to $\Gamma_k$ for some $k$. But then $\Gamma_k$ would be inconsistent as $\Gamma_k \vdash \varphi$ and $\Gamma_k \vdash \neg\varphi$, which cannot happen by construction. So $\Gamma^{+}$ is ND-consistent. - Now we need to show $\Gamma^{+}$ is maximally consistent. Say $\Gamma^{+} \cup \{\varphi\}$ is consistent. $\varphi$ must have appeared in our enumeration of $\textrm{Sen}(\mathcal{L}_1)$ at some point, i.e. $\varphi = \Phi_k$ for some $k$. $\Gamma^{+} \cup \{\Phi_k\}$ is consistent, and $\Gamma_k \subseteq \Gamma^{+}$, so it follows that $\Gamma_k \cup \{\Phi_k\}$ is consistent (subsets of consistent sets are consistent). So by our recursive construction of $\Gamma_{k+1}$, we have $\varphi = \Phi_k \in \Gamma_{k+1} \subseteq \Gamma^{+}$, so $\varphi \in \Gamma^{+}$. Hence $\Gamma^{+}$ is maximally consistent.
So now we have a way of making a maximally consistent set.
Satisfying a Maximally Consistent Set
We showed earlier maximally consistent sets treat membership almost identically to how sentences are true in a structure. As such, it shouldn't be surprising that we can create a structure that exclusively revolves around a maximally consistent set.
Completeness Lemma 2: If $\Gamma$ is a maximally consistent set, then there's an $\mathcal{L}_1$ structure $A_{\Gamma}$ such that $A_{\Gamma} \vDash \Phi$ iff $\Phi \in \Gamma$.
Proof: We prove this by giving an explicit structure: for a sentence letter $\alpha$, let $A_{\Gamma} \vDash \alpha$ iff $\alpha \in \Gamma$. We now show with induction on the complexity of sentences, that for all sentences $\Phi$ we still have $A_{\Gamma} \vDash \Phi$ iff $\Phi \in \Gamma$.
Base Case: We defined $A_{\Gamma}$ by satisfying sentence letters our condition for sentence letters, so the base case holds.
Inductive Hypothesis: Say this holds up to complexity $n$, and $\Phi$ is of complexity $n+1$. As with so many proofs before, there are 5 cases to consider, one for each connective in $\mathcal{L}_1$. The key tool we'll use is the Generalized Membership Lemma for maximally consistent sets.
$\underline{\Phi = \neg \Psi}:$ $\Gamma$ is maximally consistent by assumption, so $\Phi = \neg \Psi \in \Gamma$ iff $\Psi \notin \Gamma$. By the inductive hypothesis, $A_{\Gamma} \vDash \Psi$ iff $\Psi \in \Gamma$, so we deduce $A_{\Gamma} \nvDash \Psi$. Thus, by the semantic rule for $\neg$, we get $A_{\Gamma} \vDash \neg\Psi = \Phi$.
$\underline{\Phi = \Psi_1 \wedge \Psi_2}:$ $\Phi = \Psi_1 \wedge \Psi_2 \in \Gamma$ iff $\Psi_1 \in \Gamma$ and $\Psi_2 \in \Gamma$. By the inductive hypothesis then, $A_{\Gamma} \vDash \Psi_1$ and $A_{\Gamma} \vDash \Psi_2$. By the truth rules for $\wedge$, $A_{\Gamma} \vDash \Psi_1 \wedge \Psi_2$, and so $A_{\Gamma} \vDash \Phi$.
The other connectives are more of the same of what we've done before. Hence we can create a structure that exactly and only satisfies members of a maximally consistent set.
The Proof of Completeness
We've proven a lot about maximally consistent sets, and how they share a lot of properties to structures, but we've actually done pretty much all the work we need to fully prove the completeness of $\mathcal{L}_1$.
Completeness Theorem: If $\Gamma \vDash \Phi$, then $\Gamma \vdash \Phi$.
Proof: We'll prove the contrapositive: if $\Gamma \nvdash \Phi$, then $\Gamma \nvDash \Phi$. So suppose that $\Gamma \nvdash \Phi$. As we've seen many times before, if $\Gamma \nvdash \Phi$, then $\Gamma \cup \{\neg \Phi\}$ is consistent. By Completeness Lemma 1, we can make a maximally consistent set $\Gamma^{+}$ out of $\Gamma \cup \{\neg\Phi\}$ i.e. $\Gamma \cup \{\neg\Phi\} \subseteq \Gamma^{+}$. By Completeness Lemma 2, we can find a structure $A$ such that $A \vDash \varphi$ iff $\varphi \in \Gamma^{+}$. Since $\Gamma \cup \{\neg\Phi\} \subseteq \Gamma^{+}$, we have $A \vDash \Gamma$ and $A \vDash \neg\Phi$. By the semantic rule for $\neg$, we also have $A \nvDash \Phi$. Thus by the definition of entailment $\Gamma \nvDash \Phi$.
It's a relatively short proof, but that's mostly because we shoved a lot of the proof into the Completeness Lemmas 1 and 2. Not to mention, I don't know about you, but it is definitely not obvious to me that maximally consistent sets would be the tool that paved the path forward to prove completeness, let alone even have the intuition that $\mathcal{L}_1$ is complete. To realize that satisfiability in a structure is like membership in a maximally consistent set is already impressive, but to then think to actually link the two for this proof is very slick.
As a final aside, we can now deem $\mathcal{L}_1$ as having special status:
Adequacy Theorem: $\Gamma \vdash \Phi$ if and only if $\Gamma \vDash \Phi$.
Completeness of Other Logics
As before, I won't go into full detail, but $\mathcal{L}_2$ and $\mathcal{L}_=$ are likewise both complete logics as well. To extend the proof of completeness, it is very similar to how we would extend it for soundness, needing to just account for the quanitifers $\forall$ and $\exists$.
- First we would need to extend the Generalized Membership Lemma:
- $\exists v \Phi \in \Gamma$ iff $\Phi[t/v] \in \Gamma$ for some constant $t$
- $\forall v \Phi \in \Gamma$ iff $\Phi[t/v] \in \Gamma$ for all constants $t$
- Next would be to show that Completeness Lemma 2 still holds, that is, every maximally consistent set of $\mathcal{L}_2$ sentences is satisfiable
- Then the proof for completeness remains the same as before with $\mathcal{L}_1$
Part 4: What's Next?
This is where my logic sequence ended this year. But of course that does not mean that this is where logic as a field stops, too.
More To Be Studied!
Even before considering other logics or flaws within our current one, there is still many, extremely important results to be studied within $\mathcal{L}_1$, $\mathcal{L}_2$, and $\mathcal{L}_=$.
Compactness
One particularly strong result that deserves its own post is the Compactness Theorem:
Compactness Theorem: If every finite subset of a set of sentences $\Gamma$ is satisfiable, then the whole set $\Gamma$ is satisfiable.
We've considered finite sets of sentences a lot already (as that's what proofs required of us), and the Compactness Theorem trivially holds for them since if $\Gamma$ is finite, then $\Gamma \subseteq \Gamma$ is a finite subset of itself. But for infinite sets of sentences, it's not entirely clear when they are satisfiable or not, and Compactness gives us a more tractable way of evaluating satisfiability.
The contrapositive gives us the equivalent formulation:
Compactness Theorem: If $\Gamma$ is unsatisfiable, then there is a finite subset $\Gamma^{\textrm{fin}} \subseteq \Gamma$ that is unsatisfiable.
And this is guaranteed to hold for infinite sets, while it isn't for finite! Consider the unsatisfiable set $\{P, \neg P\} \vDash$ with clearly having its subsets (except itself) satisfiable. This has the immediate consequence that every argument $\Gamma \vDash \Phi$ can be captured in a finite argument.
Alternate Form of Compactness: If $\Gamma \vDash \Phi$, then $\Gamma^{\textrm{fin}} \vDash \Phi$.
Proof: If $\Gamma$ is finite already, then the claim holds as it is. So consider $\Gamma$ to be infinite. Recall that $\Gamma \vDash \Phi$ iff $\Gamma \cup \{\neg \Phi\}$ is inconsistent. Then by Compactness, there is a finite subset $\Gamma^{\textrm{fin}} \cup \{\neg\Phi \}$ that is inconsistent. $\neg\Phi$ must be in this set as $\Gamma$ is satisfiable by assumption of $\Gamma \vDash \Phi$, so $\Gamma^{\textrm{fin}}$ is always satisfiable (if $\Gamma$ is unsatisfiable, then it entails everything, and then by Compactness there's a finite susbet that's also unsatisfiable that entails everything). Since $\Gamma^{\textrm{fin}} \cup \{\neg\Phi \}$ is inconsistent, then $\Gamma^{\textrm{fin}} \vDash \Phi$. $ \ \blacksquare$
Finally, it's worth noting that Compactness quickly follows from any logic that is both sound and complete:
Proof of Compactness:
There are more ways to prove and apply Compactness, but that's for another day.
Löwenheim-Skolem Theorem
Löwenheim-Skolem Theorem: If $\Gamma$ is a set of $\mathcal{L}_=$ sentences with an infinite structure with cardinality $\omega$, then
- (Upward) $\Gamma$ has a structure of every cardinality $\omega' > \omega$
- (Downward) $\Gamma$ has a countable structure
The proofs found can be found in Elements of Deductive Logic (which only hold in first-order logic!), but there's an interesting paradox that comes along with it:
Skolem's Paradox: The Löwenheim-Skolem Theorem says that no first-order theory can limit what the size of the structures that satisfy it. Set theory is a first-order theory, so the theorem would say that there is a countable structure that satisfies set theory. But set theory entails that there are uncountable sets as well. How can a structure with only countably many elements satisfy something that is uncountable?
I'll leave you to think about that, but the resolution to this dilemma (also in Eagle) leads to what is now known as the non-absoluteness of set theory; a set may be uncountable relative to one structure, but countable to another.
Lindström's Theorem
We've looked at different ways logic can be limited in some math-y ways, like with expressive adequacy. The previous two theorems above give some more implicit restrictions on what a first-order logic can do. Compactness says that $\mathcal{L}_=$ can't discern finite sets from "pseudo-finite" (infinite sets whose finite subsets are satisfiable), and Löwenheim-Skolem says that it can't differentiate cardinalities of a structure. However, Lindström's theorem tells us that given these two restrictions of satisfying Compactness and (specifically the downward) Löwenheim-Skolem theorem, first-order logic is actually the strongest logic with these restrictions. Different definitions can yield different results, but analyzing the relative strength of logics is an area to still explore. Lindström uses the idea of overlapping "good structures" between two logics to determine their relative strengths.
Natural Language and Grice's Maxims
Remember, we started building logic with the intention to formalize English and natural language arguments. But obviously our formalizations above can only go so far, and one of the first, early signs of the "weirdness" logic might bring with it is the case of expressing, "If… then…" If you might recall we had the following truth tables:
To get rid of those question marks, we decided to use $\rightarrow$, since it was easier to assign the case of vacuous more than anything else. So the only real information $\rightarrow$ carries is when it evaluates to false, telling us when one fact definitely does not result in another fact. For this reason, we call $\rightarrow$ the material implication as it only really cares about the current state of the actual world: if something $\Phi$ is true in our world and another thing $\Psi$ is false, it cannot be the case that in our world $\Phi \rightarrow \Psi$.
But that's not really how we usually use "If… then…" When someone uses "if", it does not necessarily mean that they know that fact is true, but they're supposing that it's true; "if" can denote a hypothetical. Compare the following conditionals:
- If Apple merges with Google, then Samsung does not have a monopoly on smartphones.
- If Apple merged with Google, then Samsung would not have a monopoly on smartphones.
The use of "would" in the second case indicates something that hasn't actually happend, but describes a perfectly understandable situation that we can still parse information from. In the first sentence, $\rightarrow$ would deem that a true sentence since our antecedent is false i.e. Apple and Google have not merged in the actual world. But in the second case, that sentence is false, since it is conceivable that even if Apple and Google merged in an alternate universe, it is possible that Samsung could still be the number one seller of smartphones.
The counterfactual implication, denoted by the fancy symbol $\square \!\! \rightarrow$, captures these hypothetical situations we use all the time that our material implication just fails to render accordingly.
Grice's Maxims
Note what we introduced above with $\square \!\! \rightarrow$ had no concrete semantics attached to it; our idea of hypotheticals, and "would" only arose out of what we understand in natural language, instead of something problematic from within the logic (or even English) itself. As such, this doesn't really give us a new truth table or anything, and unfortunately for logic, there are quite a few of these tacit rules to English.
For example, if I say, "Either I will pass my job interview, or the other candidate will get in," there's an additional piece of information that's communicated beyond just the two possibilities: I don't know which case will occur. And according to our semantic rules for $\vee$ that formalize "…or…", I could entail a disjunction by knowing a disjunct. That is, if I know $\Phi$, I certainly also know $\Phi \vee \Psi$ according to the truth table for $\vee$; $\Phi \vDash \Phi \vee \Psi$. Strictly speaking then, saying "I will pass my job interview" just contains more information as not only does it entail that "or" sentence I said at the beginning, but also an additional sentence (itself).
So if someone was to use any statement involving "…or…", we would expect them to be telling us exactly as much information as we need to get their message across, that being that they just don't know either side of the "…or…" statement since if they did, they would just say it.
Paul Grice (1975) formalized these cooperative principles of communication into what is now know as Grice's maxims that describe these underlying, hidden aspects of language that we always use, but never explicitly write out or explain (since they are just expected). In no particular order, they are:
- Quantity: contribute as much information as is required without excess or lack of details.
- Quality: contribute only as much as one knows and has evidence to be truthful.
- Relation: contribute to the subject matter at hand; only be relevant.
- Manner: be direct, clear, and avoid obscurity and esoteric constructions and words.
Notably the maxim of quantity is what poses a difficulty for our logical language, as seen with "…or…" and $\vee$. Incorporating these maxims, though, is a possible direction one could look to enhance or strengthen their logic's utility and applicability.
Extensions of Logic
Our logic above has done pretty well for what it needs to do concerning truth, and has found its way into computer science and discrete math as well by its very nature. But there are some arguments that go beyond truth alone.
Higher-Order Logics
A natural—and actually well-practiced—addition to logic are higher-order types. What we've been working with is known as first-order logic, as we can only quantify over objects. That is, $\forall$ and $\exists$ only ranges over possible, single objects that satisfy a formula. But, there are many things we can say beyond just objects. For example, in math we often able to make claims about sets of numbers. The least-upper-bound property of the real numbers states that every nonempty subset of the real numbers has a least upper bound (i.e. the supremum exists).
Or even simpler, for any property $P$ and any object $x$, it must be the case that $Px \vee \neg Px$.
Second-order logic is the upgrade we need that allows us to start quantifying over sets of objects. In first-order logic, it was predicates that took on the semantic value of sets of objects, so naturally second-order quantification looks like quantifying over predicates. So for our above example, it would look like: $\forall P \forall x(Px \vee \neg Px)$ where $P$ is now a variable standing in place for a predicate.
Quantifying over predicates/properties/sets of objects allows us to say quite a bit more as you'd expect. Earlier we mentioned the difference between numerical identity and qualitative identity, but now we are able to formalize how they relate to each other:
The Indiscernibility of Identicals: $\forall x \forall y (x = y \rightarrow \forall P(Px \leftrightarrow Py))$
- If two things are numerically identical, then they certainly have all the same properties
The Identity of Indiscernibles: $\forall x \forall y (\forall P(Px \leftrightarrow Py) \rightarrow x = y)$
- If two things have all the same properties, then they should be the same object
These are known as Leibniz's laws, and as discussed, the first is usually uncontested, while the second is more controversial. Whatever the case may be, second-order logic has given us a way to more clearly pick apart these claims.
But why stop there? First-order logic allowed us to quantify over objects; second-order logic allowed us to quantify over sets of objects (predicates). third-order logic allows us to quantify over sets of sets of objects, and the pattern continues. Second-order logic in particular is the most widely "used" from mathematics to computer science, but it should not be held to be necessarily "better" than first-order logic: second-order logic is actually incomplete.
Higher-order logic has its pulls and drawbacks, but it is a natural step from what we've looked at today, especially if you're interested in the foundations of mathematics and set theory.
"Universal" Logics
We already saw with the counterfactual conditional $\square \!\! \rightarrow$, there are already some obvious cases our logic lacks. Not to mention, the idea of possible and necessarily pops up all the time in philosophy and arguments, that it's a little disconcerting that we can't already formalize them.
Modal logic extends our logic precisely in this way, with two new quantifiers: We express, "It is possible the case that P," as $\square P$, and, "It is necessarily the case that P," as $\lozenge P$. The semantics of $\square$ and $\lozenge$ take our ideas of a structure as a model of the universe a little too literally. We say $\square P$ is true if there is a possible world in which $P$ is true, and we say $\lozenge P$ is true if in all possible worlds $P$ is true. The notion of what a possible world is by nature just vague, but it is an interesting one to consider. Ignoring semantics, we can already deduce a lot with these operators:
- $\neg \lozenge \Phi \equiv \square \neg \Phi$
- If it is not necessary that $\Phi$ occurs, there is a possible world in which $\Phi$ does not occur (i.e. $\neg \Phi$ occurs)
- $\neg \square \Phi \equiv \lozenge \neg \Phi$
- If it is not possible that $\Phi$ can occur, then it is necessarily the case that $\Phi$ does not occur (i.e. $\neg \Phi$ occurs)
As might be expected by the way we discussed their semantics, $\square$ and $\lozenge$ act a lot like $\exists$ and $\forall$ respectively.
Other extensions include temporal logics, that allow us to formalize time-sensitivity as well. The statement, "It is raining right now," might have a constant meaning, but whether it is true or not changes based on time, thus motivating the formalization of predicates like "eventually", "always", "until", and others that delineate time.
Free logics allow us to abandon the need to have constants to actually mean anything, or even have a non-empty domain. Just because we can talk about an imaginary, non-real thing, like a unicorn (i.e. has the body of a horse, has one horn, etc.), does not necessarily mean that a unicorn exists. Yet, if we allow unicorns into our domain of a structure to logically discuss them, it would appear that we would be claiming the existence of a mythical creature, which becomes quite useful when discussing metaphysics and any ontology or description of existence (in a way, free logic is all about specifying the conditions of existence.).
Multivalue and Fuzzy Logics
We have only ever considered two possible ways to evaluate a sentence: it is either true or false. But is that really the case? Sounds kind of insane to even try and conceive of something else a sentence could be, but consider the following sentence:
If it is true, then it declares itself false. If it is false, then it declaring that it is false is wrong, so it is true. The cycle continues forever and ever, without ever resolving itself to one of our prescribed truth values.
So some propose a solution that include a third, deviant truth value that allows us to ascribe some sentences as neither true nor false in a 3-value logic. Or another unintuitive solution is to allow degress of truth, i.e. the above sentence might be considered .5 true. Giving truth values between 0 and 1 is the cornerstone of fuzzy logic, which is usually used to describe when there is inexact information. However, don't confuse this number of truth as that of probability; it's not that this sentence is true only half the time, but rather that it's considered only half true since it is vague. Probability usually is associated with ignorance (lack of information; i.e. "the coin will land heads with probability .5" is said since we don't have knowledge of the future) as opposed to a lack of clarity. This notion is similar to the idea of degrees of membership in fuzzy set theory.
Altering the Axioms
The tautology $P \vee \neg P$ is quite a natural one. "Either it is or it is not." What other option could there be? Even in math we use double negatives multiplying to a positive, so positive and negative numbers seems to be the only cases possible. The law of excluded middle just seems to be a fact of the universe, that falls perfectly in line with our proofs and semantics for the classical logic we've been looking at.
But I've alluded throughout the post that some people do not always accept this as a given. Intuitionistic, or constructive logic, rejects the law of excluded middle, and argues that $\neg \neg P \nvDash P$, which come as standard inference rules that we can derive. The name comes from the fact that this doctrine encourages literal demonstrations of proof: if you have a proof of $P \wedge Q$, you literally have a proof of both $P$ and $Q$; a proof of $P \vee Q$ means one has a proof of $P$, or has a proof of $Q$.
Even more (ironically) unintuitive, we lose the ability to use proof by contradiction, as that relies on the ability to claim that if an assumption is wrong, its negation is true. So for classic proofs like the irrationality of $\sqrt{2}$, intuitionists would claim that all that's been proven is that $\sqrt{2}$ is not rational, not necessarily that it is irrational.
Picking and choosing what axioms, entailments, or laws one accepts of course changes what meaning and truth will look like to them, and can lead to some interesting, tenable persepctives that hold real weight and become the focus of entire areas of philosophy.
Conclusion
This post does not replace the two textbooks outlined above. If anything, it is only a simple supplement that gives a high-level overview of all the major conceptst to newcomers of formal logic, and a quick review source for those who have already studied it. At the very least, it'll be a quick reference for me, and future posts, as logic really has forced me to reconsider what I thought to be "staple truths", not just in math, but life in general. We'll definitely revisist logic in the future whether it be from a computer science perspective with decidability and algorithms, certain shortcuts in math, or just more theory in logic itself. The way logic has developed in such an abstract way lends itself to be applied anywhere, it's just a matter of thinking about how, as it almost certainly can be.